NICE-SLAM¶
约 1340 个字 预计阅读时间 4 分钟
Abstract
 NICE-SLAM: Neural Implicit Scalable Encoding for SLAM
NICE-SLAM: Neural Implicit Scalable Encoding for SLAMIdea¶
Introduction¶
- Real-Time
- 大场景有效,iMAP 或 learning-based 方法做不到
- robust,对 nosie 和未观测到位置鲁棒,合理预测
- 最大的创新点:multilevel grid-based features(基于网格的多层特征),其余的 idea 就是优化方法,如何 mapping、tracking、如何加速,联合训练 + 分层训练,nerf 采样方法等等
- 采用了三维栅格地图,每个栅格保存局部特征,用 decoder 将特征解码即可恢复出场景,因此即使场景面积很大也不存在网络遗忘的问题
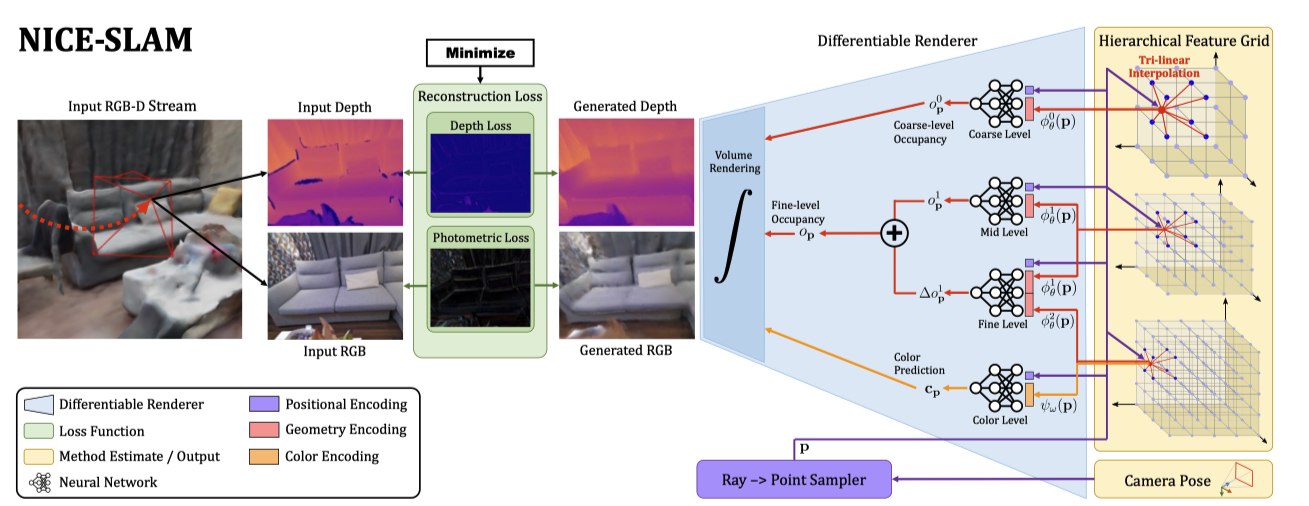
Hierarchical Scene Representation¶
- 上图中的右边部分,从左向右看分别是 MLP 和 feature grid;
- 从上往下看,有四个部分,前三部分预测几何信息,第四部分预测颜色:
- coarse-level: 为提升效率,grid 采样块大且独立出来,用于预测(填补空洞,例如地板墙面)
- mid-level+fine-level: 先经过 mid-level 预测出一个占用率 \(o\),使用 fine-level 预测出 \(\Delta o\),两者相加得到最终占用率。从图中可以看出 fine-level 的输入是小网格、小小网格 ...
- color-level:与前三层不同,color-level 的 decoder 和 encoder 都在更新,而前三层固定了 MLP 只更新特征网络,这样有助于大场景的构建,MLP 不会被新的特征影响。此处的 MLP 是 CNN + MLP 预训练后,单独取 MLP 出来获得。因此 color-level 就会存在颜色被更新的问题,构建大场景时就不能有颜色信息。
Depth and Color Rendering¶
- 借鉴 NeRF 的方法获得 depth 和 color
- 对于一条光线,使用分层和均匀采样一个得到 N 个点,对于这 N 个点都估计出一个权重 \(w_i\)(表示光线到 i 终止的概率
) ,显然概率越大,这一点越容易是物体。 - coarse 层 和 fine 层的权重:
\[
w_i^c = o_{p_i}^0 \prod_{j=1}^{i-1}(1-o_{p_j}^0) = o_{p_i} \prod_{j=1}^{i-1}(1-o_{p_j})
\]
- 由权重可以得到渲染后的深度值和颜色值:
\[
\hat{D}^c = \sum_{i=1}^N w_i^c d_i, \quad \hat{D}^f = \sum_{i=1}^N w_i^f d_i, \quad \hat{I} = \sum_{i=1}^N w_i^f \mathbf{c}_i
\]
- 其中,\(d_i\) 是采样点到原点的距离。进一步还可以求出沿光线方向的深度方差:
\[
\hat{D}_{var}^c = \sum_{i=1}^N w_i^c (\hat{D}^c - d_i)^2 \quad \hat{D}_{var}^f = \sum_{i=1}^N w_i^f (\hat{D}^f - d_i)^2
\]
Mapping and Tracking¶
- 主要基于 Hierarchical Scene Representation 和相机位姿的参数 \(\theta\) 和 \(\omega\) 的优化
。 (损失函数) -
Mapping:优化 scene representation
- 建图阶段包含两个 loss
- 几何 loss
\[ \mathcal{L}_g^l=\frac{1}{M}\sum_{m=1}^M \left | D_m - \hat{D}_m^l \right |, \quad l\in\{c,f\} \]- 光度 loss
\[ \mathcal{L}_p = \frac{1}{M} \sum_{m=1}^M \left | I_m - \hat{I}_m \right | \]-
通过从当前帧和关键帧中均匀采样共 M 个像素,最小化 loss。优化顺序:
- 使用 \(\mathcal{L}_g^f\) 优化 mid-level feature grid \(\phi_\theta^1\)
- 使用 \(\mathcal{L}_g^f\) 优化 mid-level 和 fine-level feature grid \(\phi_\theta^1\) 和 \(\phi_\theta^2\)
- 使用 local bundle adjustment(BA 局部约束调整)联合优化所有 level 的 grids,color decoder,相机外参 \(\{\mathbf{R}_i, \mathbf{t}_i\}\) 在第 K 个关键帧处,使用如下:
\[ \min_{\theta,\omega,\{\mathbf{R}_i,\mathbf{t}_i\}}(\mathcal{L}_g^c+\mathcal{L}_g^f+\lambda_p\mathcal{L}_p) \]
作者解释这么做的原因
外分辨率的外观和 fine-level 都依赖于 mid-level 所以先优化 mid 能够加快收敛。此外,使用并行三个线程加速优化过程:coarse-level,mid+fine+color,tracking(下个步骤
-
Tracking:优化当前帧的 camera poses,即 \(\{R,t\}\)
- 在当前帧中采样 \(M_t\) 个像素点使用如下 loss:
\[ \min_{\mathbf{R},\mathbf{t}} (\mathcal{L}_{g \_ var}+\lambda_{pt}\mathcal{L}_{p}) \]- 其中,对几何损失做了修改,修改 \(\mathcal{L}_{g \_ var}\) 如下:
\[ \mathcal{L}_{g \_ var}=\frac{1}{M_t}\sum_{m=1}^{M_t}\frac{\left|D_m-\hat{D}_m^c\right|}{\sqrt{\hat{D}_{var}^c}}+\frac{\left|D_m-\hat{D}_m^f\right|}{\sqrt{\hat{D}_{var}^f}} \]
使用 \(L_{g \_ var}\) 的好处
The modified loss down-weights less certain regions in the reconstructed geometry [46, 62], e.g., object edges. 修改后的 loss 降低了重建场景中不确定区域的权重。
- Robustness to Dynamic Objects:当场景中出现动态物体时,NICE-SLAM 可以通过过滤像素点来忽略这个动态物体,因为在动态物体上采样得到的像素点 loss 值会很大
。 (这一点可以利用起来)
Keyframe Selection¶
- 类似 iMAP 一样,维护一个全局的关键帧,基于新增信息来添加新的关键帧,但不同的是,包括 的关键帧当优化场景几何时需要与当前帧有视觉重叠。
- 这种选择策略不仅确保当前视图之外的几何保持静态,而且还会导致非常有效的最佳化问题,因为每次只优化必要的参数。
- 实际上,首先随机采样像素并使用优化的相机姿势反向投影相应的深度。然后,将点云投影到全局关键帧列表中的每个关键帧。从那些有点投射到的关键帧中,我们随机选择 K−2 帧。此外,还在场景表示优化中包括最近的关键帧和当前帧,形成 K 个活动帧的总数。
Experiments¶
- 数据集:Replica、ScanNet、TUM RGB-D、Co-Fusion
- Baseline:TSDF-Fusion、DI-Fusion、iMAP、BAD—SLAM、Kintinuous、ORB-SLAM2
Reference¶
最后更新:
2024年8月8日 16:25:42
创建日期: 2024年8月8日 16:25:42
创建日期: 2024年8月8日 16:25:42