BERT¶
约 1558 个字 5 张图片 预计阅读时间 5 分钟
Abstruct
- BERT 作为 NLP 预训练模型里的经典模型之一,效果非常好。
- BERT 的模型代码和模型参数开源,都可以基于这个强大的模型组件搭建自己的 NLP 系统,也节省开始训练语言处理模型所需要的时间、精力、知识和资源。
- BERT 的全称是 Bidirectional Encoder Representation from Transformers,即双向 Transformer 的 Encoder,因为 decoder 是不能获要预测的信息的。
- 模型的主要创新点都在 pre-train 方法上,即用了 Masked LM 和 Next Sentence Prediction 两种方法分别捕捉词语和句子级别的 representation。
Introduction¶
BERT 首先在大规模无监督语料上进行预训练,然后在预训练好的参数基础上增加一个与任务相关的神经网络层,并在该任务的数据上进行微调,最终取得很好的效果。
BERT 的训练过程可以简述为:预训练 + 微调(finetune
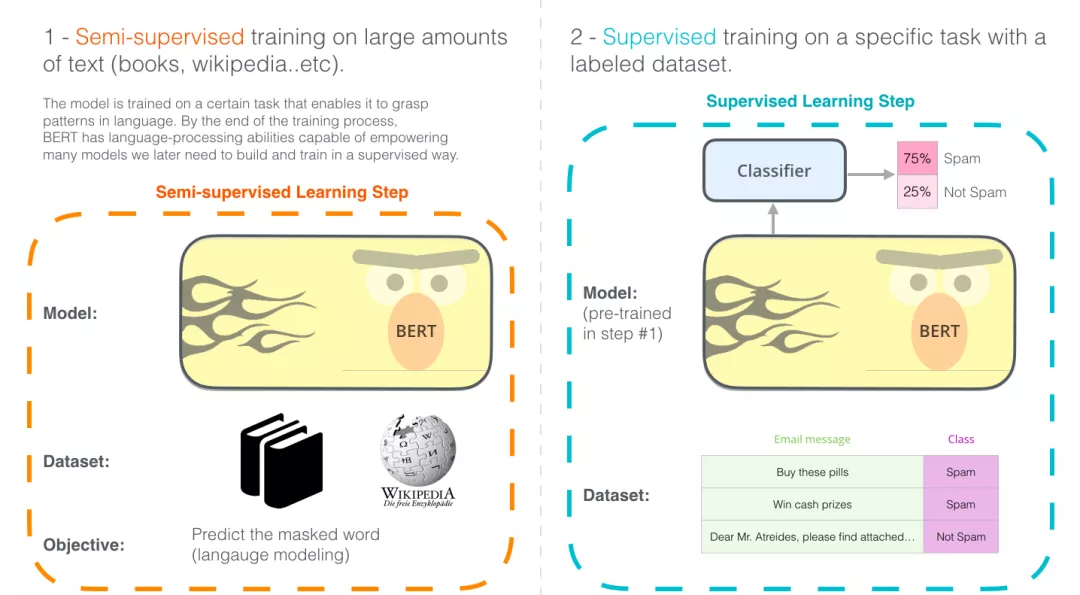
模型结构 ¶
BERT 模型的结构如下图最左:
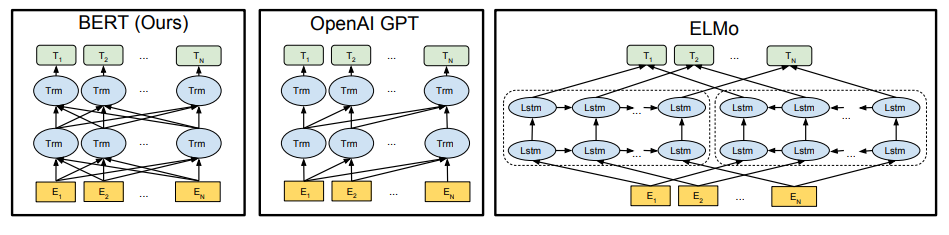
- 对比 OpenAI GPT,BERT 是双向的 Transformer block 连接,就像单向 RNN 和双向 RNN 的区别,效果会更好。
- 对比 ELMo,虽然都是“双向”,但目标函数不同。
- ELMo 是分别以 \(P(w_i|w_1,...,w_{i-1})\) 和 \(P(w_i|w_{i+1},...,w_n)\) 作为目标函数,独立训练出两个 representation 然后连接
- BERT 是以 \(P(w_i | w_1,...,w_{i-1},w_{i+1},...,w_n)\) 作为目标函数训练 LM
命名表示层数为 L(Transformer Blocks
- BERT_base(L=12,H=768,A=12; parameters=110M)
- BERT_large(L=24,H=1024,A=16; parameters=340M)
Embedding¶
这里的 Embedding 由三种 Embedding 求和组成:
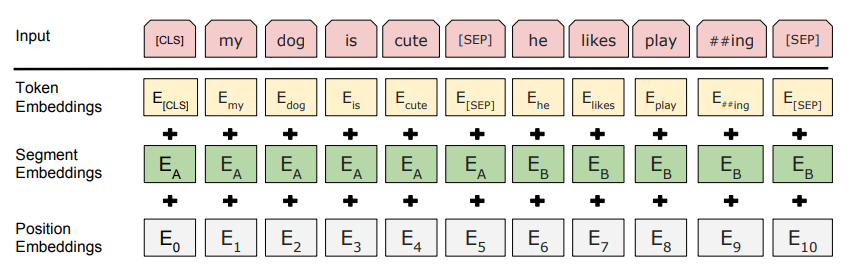
Token Embedding:词向量,第一个单词是 CLS 标志,可以用于之后的分类任务Segment Embedding:句子向量,用于区分两个句子,因为预训练不光做 LM 还要做以两个句子为输入的分类任务Position Embedding:位置向量,用于区分单词在句子中的位置,和之前的 Transformer 不一样,不是三角函数而是学习出来的
Pre-training¶
Masked LM (MLM)¶
- 第一步预训练的目标就是做预言模型,从上文模型结构中看到了这个模型的不同,即 bidirectional。
为什么要 bidirectional
如果使用预训练模型处理其他任务,那人们想要的不止某个词的左边的信息,而是左右两边的信息,而考虑到这点的模型 ELMo 只是将 left-to-right 和 right-to-left 分别训练拼接起来。直觉上来讲我们其实想要一个 deeply bidirectional 的模型,但是普通的 LM 又无法做到,因为在训练时可能会“穿越”,所以作者用了一个加 mask 的 trick。
- 在训练过程中作者随机 mask 15% 的 token,而不是把像 CBOW 一样把每个词都预测一遍。最终的损失函数只计算被 mask 掉那么 token。
- mask 如何做也是有技巧的,如果一直用标记 [MASK] 代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机 mask 的时候 10% 的单词会被替代成其他单词,10% 的单词不替换,剩下 80% 才被替换为 [MASK]。要注意的是 Masked LM 预训练阶段模型是不知道真正被 mask 的哪个词,所以模型每个词都要关注。
为什么这么分配比例
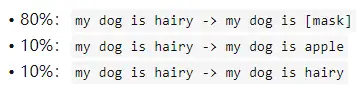
如果句子中的某个 Token100% 都会被 mask 掉,那么在 fine-tuning 的时候模型就会有一些没有见过的单词。加入随机 Token 的原因是因为 Transformer 要保持对每个输入 token 的分布式表征,否则模型就会记住这个 [mask] 是 token ’hairy‘。至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有 15%*10% =1.5%,这个负面影响其实是可以忽略不计的。
- 因为序列长度太大(512)会影响训练速度,所以 90% 的 steps 都用 seq_len=128,10% 的 steps 用 seq_len=512。
Next Sentence Prediction (NSP)¶
- 因为涉及到 QA 和 NLI 之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。
- Next Sentence Prediction(NSP)的任务是判断句子 B 是否是句子 A 的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中 50% 保留抽取的两句话,它们符合 IsNext 关系,另外 50% 的第二句话是随机从预料中提取的,它们的关系是 NotNext 的。
- 预训练的时候可以达到 97%-98% 的准确度。
- 作者特意说了语料的选取很关键,要选用 document-level 的而不是 sentence-level 的,这样可以具备抽象连续长序列特征的能力。
Fine-tuning¶
微调是简单的,因为 Transformer 中的自注意力机制允许 BERT 通过交换适当的输入和输出来建模许多下游任务 -- 不管它们涉及单个文本还是文本对。对于 NSP 任务来说,其条件概率表示为 \(P=softmax(CW^T)\),其中 C 是 BERT 输出中的 [CLS] 符号,W 是可学习的权值矩阵。
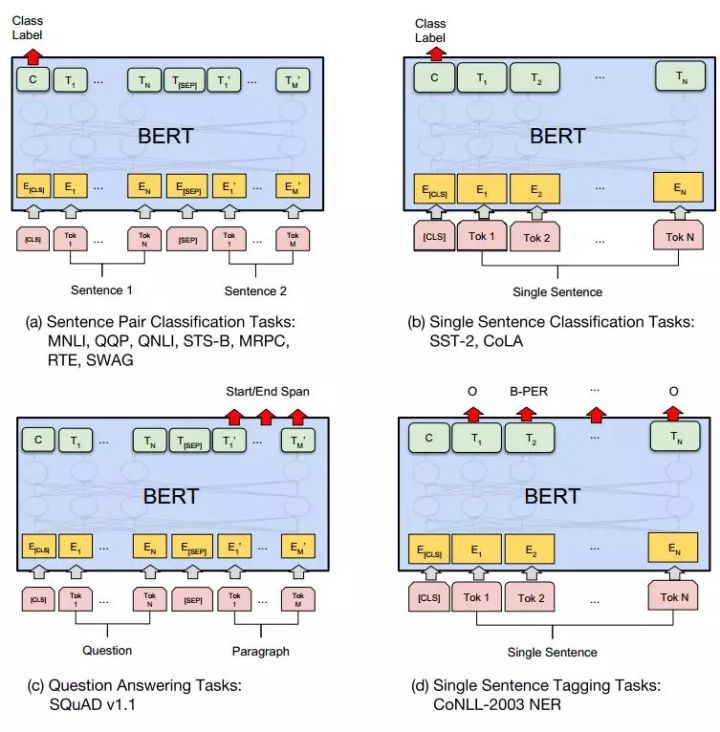
微调的任务包括:
- 基于句子对的分类任务
- 基于单个句子的分类任务
- 问答任务
- 命名实体识别 NER
下图展示了 BERT 在 11 个不同任务中的模型,它们只需要在 BERT 的基础上再添加一个输出层便可以完成对特定任务的微调。这些任务类似于我们做过的文科试卷,其中有选择题,简答题等等。图 3 中其中 Tok 表示不同的 Token,E 表示嵌入向量,\(T_i\) 表示第 i 个 Token 在经过 BERT 处理之后得到的特征向量。
整体 Fine-Tuning 过程:
- 构建图结构,截取目标张量,添加新层
- 夹在目标张量权重
- 训练新层
- 全局微调