NeRF¶
约 2137 个字 11 行代码 12 张图片 预计阅读时间 7 分钟
Abstract
 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF: Representing Scenes as Neural Radiance Fields for View SynthesisIdea¶
Introduction¶
- 通过优化一组稀疏输入视角的连续体积场函数,实现合成复杂场景的新视角。
- 用一个全链接(非卷积)深度网络表示场景,输入是一个连续的 5D 坐标(\(x\),\(y\),\(z\),\(\theta\),\(\phi\) 空间位置和观察方向
) ,输出是该空间位置处的体积密度和视角相关的辐射强度。 - 通过查询相机光线上 5D 坐标来合成视角,并用体渲染技术将输出的颜色和密度投影到图像中。
- 由于体渲染在自然上是可微分的,优化我们的表示所需的唯一输入是一组具有已知相机姿态的图像,包括一种分层采样策略,将 MLP 的容量分配给具有可见场景内容的空间。
- 一种位置编码,将每个输入的 5D 坐标映射到更高维度的空间,以便网络可以学习表示具有更高频率的场景内容
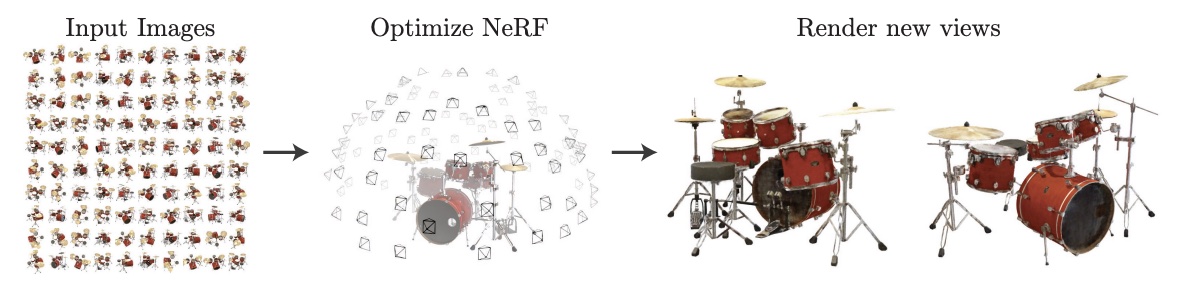
NeRF Scene Representation¶
- 下图中间的函数 \(F\) 就是图当中的神经网络,用来表示 3D 场景,这种表示方法是隐式的
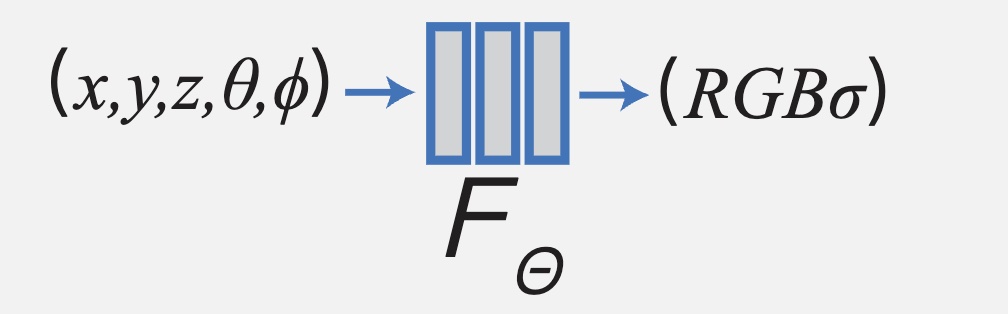
- 输入 \(x,y,z,\theta,\phi\) 是空间位置和观察方向,输出 \(RGB, \sigma\) 是颜色和密度,就能算出场景中的颜色和密度
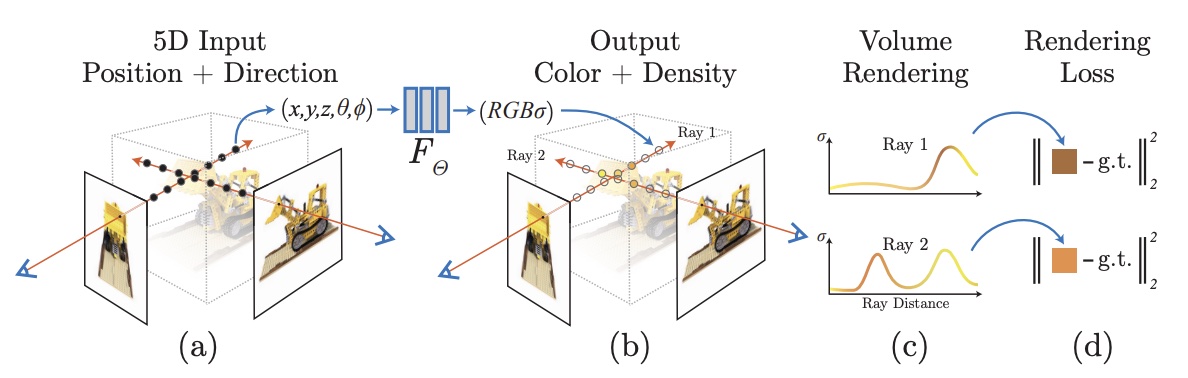
Volume Rendering¶
光线的数学表示与光线采样 ¶
一条光线上所有位置上的颜色和密度的合成,就是成像图上的像素 RGB 值,那么这条光线怎么表示?以及怎么在光线上取一些点?
nerf 的光线表示 ¶
光线是一条空间直线,准确的说是一条空间射线,表示如下
\[
\bold{r}(t) = \bold{c} + t\bold{d}
\]
- 起点坐标 \(\bold{o}\):相机中心点
- 方向向量 \(\bold{d}\):相机光线方向
- \(t\):光线上的点到起点的水平距离,\(t\) 取不同的值就是光线上不同的采样点
nerf 光线公式推导 ¶
经证明后 NeRF 的 \(t\) 取的是 z 轴距离,而不是光线的距离,而且只有中心光线方向是单位向量。
\[
\bold{r} = \bold{o} + \|z\|\bold{d}
\]
光线采样 ¶
- \(t=\|z\|\):光线上的点到起点(相机中心)的距离,\(t\) 取不同值就是光线上不同的采样点,nerf 默认取 61 个点,60 段。
- \(\bold{r}(t)\):光线上的点的三维坐标。
- \(\bold{d}\):光线方向向量,也是三个值。
Code
def get_rays(H, W, K, c2w):
i, j = torch.meshgrid(torch.linspace(0, W-1, W), torch.linspace(0, H-1, H))
i = i.t()
j = j.t()
dirs = torch.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -torch.ones_like(i)], -1)
rays_d = torch.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1)
rays_o = c2w[:3,-1].expand(rays_d.shape)
return rays_o, rays_d
#计算光线采样
z_vals = tf.linspace(near, far, N_samples)
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None]
- dirs 是相机坐标系下的光线方向。
- rays_d 是世界坐标系下的光线方向,为什么用点乘+求和:因为输入是行向量(python 没有一维列向量)不能直接像列向量那样用矩阵乘法。
- rays_o 是世界坐标系下的光线起点。
光线成像模型 ¶
怎么合成一条光线上的所有粒子的图像 ?
- 分析单点 P 对成像的贡献。P 距离线起点的距离是 t,然后能得出 P 点坐标 \(\bold{r}(t)\)
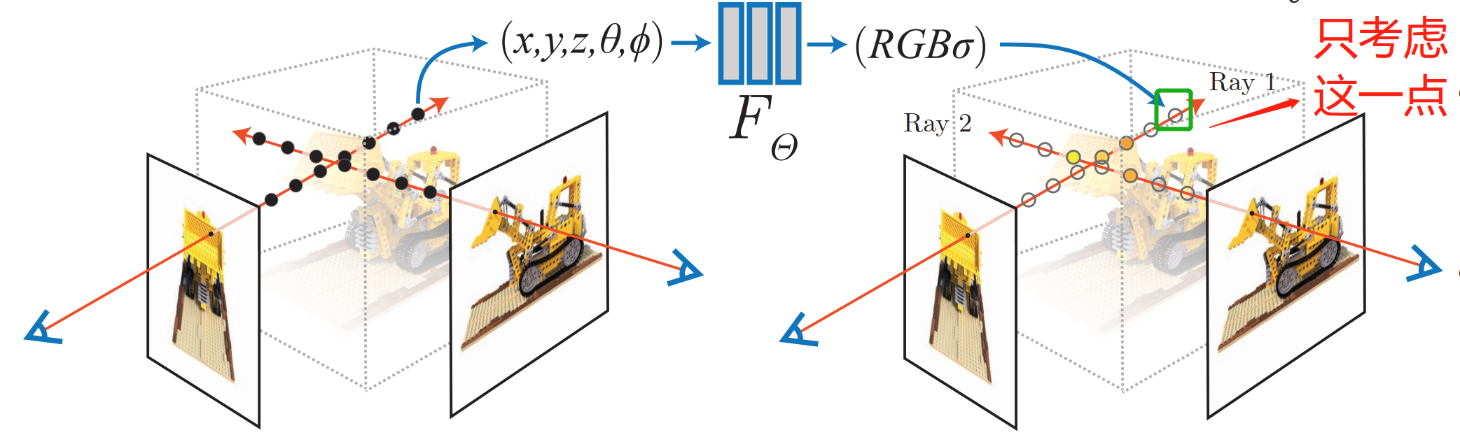
- 密度越高,透明度越低,所以单看 P 点,它的成像颜色就是 \(c \cdot \sigma\)
- \(\sigma = 1.0\):完全不透明,它的成像颜色就是 \(c \cdot 1.0=c\)
- \(\sigma = 0.0\):完成透明,它的成像颜色就是 \(c \cdot 0.0=0\)
- 同时,光线从相机出发,由于密度 \(\sigma\) 的存在,强度不断减弱,不一定能到到 P 点,到达的概率时记为 \(\bold{T}(t)\)。
- 可以想象,\(\bold{Τ}\) 应该是密度 \(\sigma\) 和距离 \(t\) 的函数
- 那么汇总到一起:场景中一点 P 对光线成像的贡献:\(\bold{T}(t) \cdot \bold{c}(\bold{r}(t), d) \cdot \sigma(\bold{r}(t))\)。
- 其中 \(\bold{r}(t)\) 是光线上点的坐标,\(\bold{d}\) 是光线方向,\(t\) 是光线上点与相机中心距离。
- 整条光线成像:知道了的单点,整条光线成像就是对光线上所有的点求积分,且考虑光线只需有限区间 \(t_n-t_f\) 之间,得光线 \(r\) 成像:
\[
C(r) = \int_{t_n}^{t_f} \bold{T}(t) \cdot \bold{c}(\bold{r}(t), d) \cdot \sigma(\bold{r}(t)) dt \ \ \ where \ \bold{T}(t) = \exp(-\int_{t_n}^{t_f} \sigma(s) ds)
\]
-
NeRF 中分段随机采样
- 计算机是无法连续积分,因此采样是需要近似离散的。
- 如果选择在光线路径上均匀采样,虽然在一定程度上近似这个积分,但这种⽅法在处理密度较⾼的区域或者快速变化的区域时效果并不好。因为这些区域可能需要更⾼的采样密度来准确地估计积分。
- ⾸先将射线需要积分的区域分为 N 份,然后在每⼀个⼩区域中进⾏均匀随机采样。这样的⽅式能够在只采样离散点的前提下,保证采样位置的连续性。
\[ t_i\thicksim\mathcal{U}{\left[t_n+\frac{i-1}N(t_f-t_n),\mathrm{~}t_n+\frac iN(t_f-t_n)\right]}. \]
Optimizing NeRF¶
Positional encoding¶
对神经网络直接输入 5D 会导致渲染效果较差,不能很好地表示颜色和几何中高频变化。
- 将输入的三维坐标进行位置编码:
\[
F_\mathcal{\theta} = F_{\mathcal{\theta}}^\prime \gamma
\\
\gamma(p)=\begin{pmatrix}\sin\bigl(2^0\pi p\bigr),\cos\bigl(2^0\pi p\bigr),&\cdots,\sin\bigl(2^{L-1}\pi p\bigr), \cos\bigl(2^{L-1}\pi p\bigr)\end{pmatrix}.
\]
Hierarchical volume sampling¶
- NeRF 的渲染过程计算量很大,每条射线都要采样很多点,但实际上,一条射线上的大部分区域都是空区域,或被遮挡的区域,对最终的颜色没有贡献。
- 因此采用一种
coarse to fine的形式,同时优化 coarse 网络和 fine 网络。先在光线上均匀采样一些点,并计算其体积密度,然后基于这些密度值进行重采样,得到更倾向于物体内部和表面的点,以提高渲染效果。
Loss Fn and Train¶
- 对于每个场景,针对单独的神经连续体积表示网络进行优化。需要场景的 RGB 图像数据集、相应的相机位姿和内参,以及场景边界(对于合成数据,使用真实的相机位姿、内参和边界,对于真实数据,使用 COLMAP 估计这些参数)
- 每次迭代,从数据集中所有像素中随机采样一个 batch 的相机光线,然后根据分层采样方法从 coarse 网络查询 \(N_c\) 个样本和从 fine 网络中查询 \(N_c + N_f\) 个昂本,再根据体渲染得到每条光线的颜色
- 损失函数仅仅是 coarse 和 fine 的渲染像素颜色与真实颜色之间的总平方差误差,同时优化 coarse 和 fine
\[
\mathcal{L} = \sum_{r \in R} \left [ \left \| \hat{C}_c(r) - C(r) \right \|_2^2 - \left \| \hat{C}_f(r) - C(r) \right \|_2^2 \right ]
\]
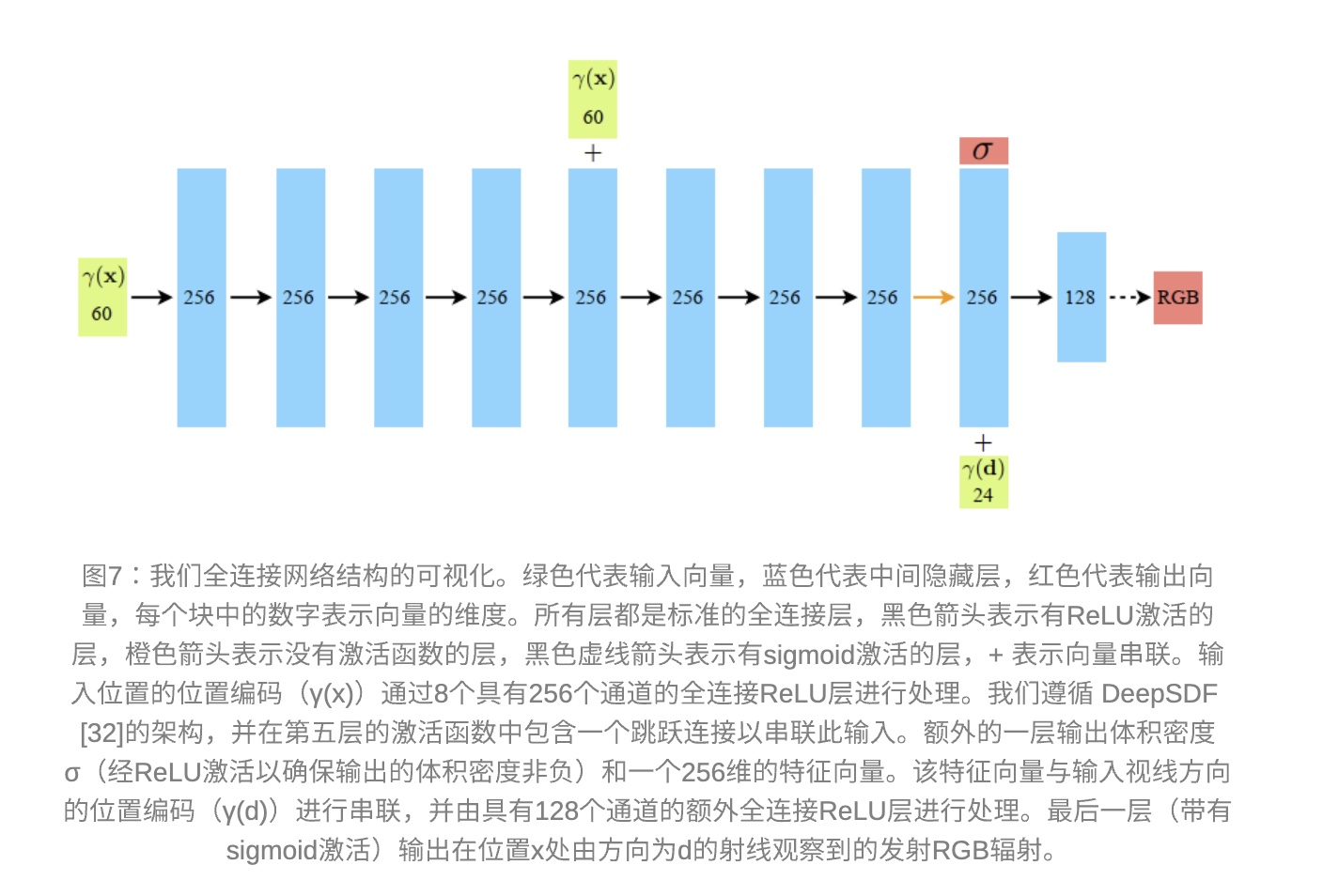
Pipeline¶
- 已知相机在不同的位置拍摄了一组目标场景的照片
。 (如果你是手机拍摄的一段视频可以用 colormap 转)

- 从相机中心开始,沿着某个像素方向发射一条光线。( 注意:跟真实的相机成像模型光线方向是相反的,但不影响 )。

- 建立一个神经网络 \(F\),输入 \((x,y,z,\theta,\phi)\) 是空间位置和观察方向,输出 \(RGB,\sigma\) 颜色和密度。就能算出场景中每个位置的颜色和密度。
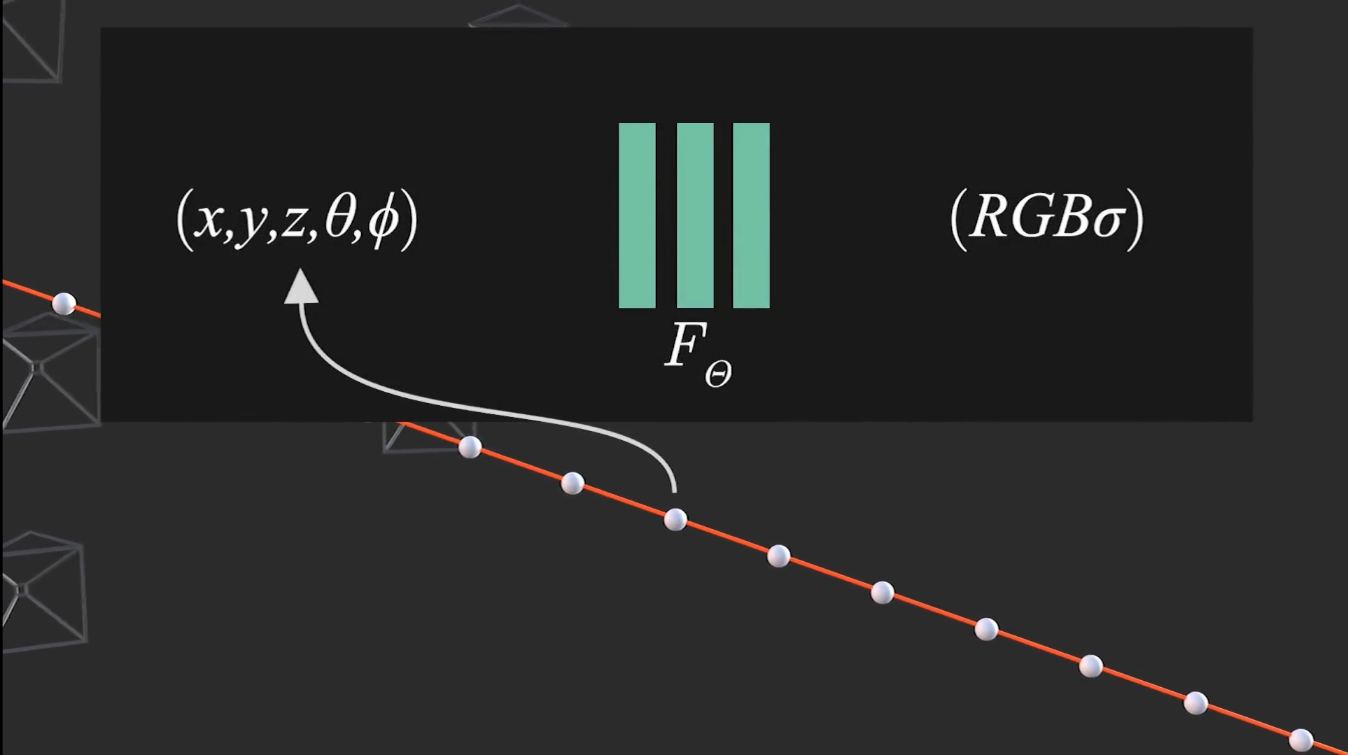
- 把这条光线上所有位置上的颜色和密度合成,就能算出图上的像素 RGB 值。
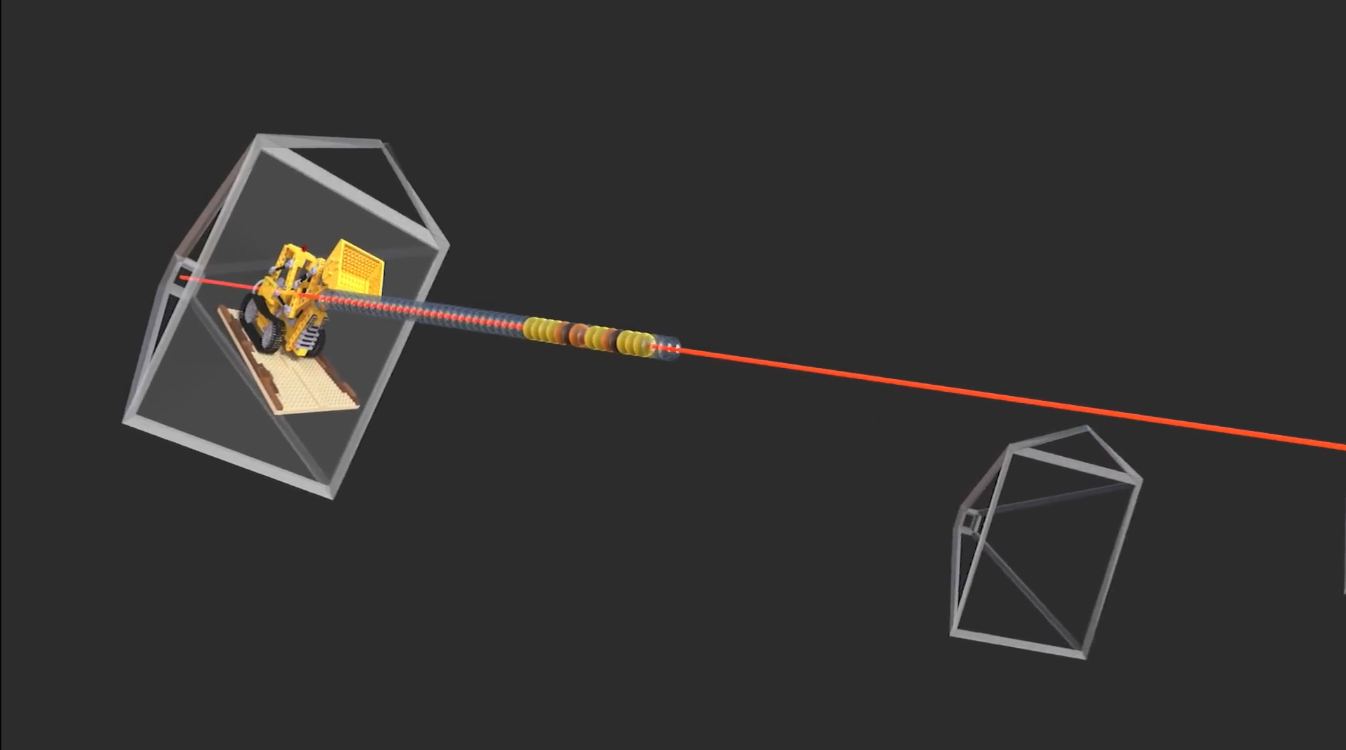
- 根据输入的一组图像上的像素 RGB 值,生成无数条光线,不断去优化可微函数 \(F\)。当优化次数足够,就可以直接使用 \(F\) 算出所有视角下图像的像素 RGB 值。

- 知道每个位置的颜色和密度,就用 Marching Cubes 算法转换为三角网三维模型。完成三维重建。

- 求得 \(F\) 就实现了三维重建,后面都是合成新视角和转换。
基本原理
- 作者首先把重建过程 \(F\) 用深度学习代替,\(F(x,y,z,\theta,\phi)=RGB\sigma\) 从(空间位置、观察方向)到(颜色、密度)的过程。
- 作者对光线成像的光学模型做了假设,建立一个数学模型。
- 根据光线成像与输入像素不同不断优化,进而优化得出 \(F\)。
算法的关键:光线成像模型。
Experiment¶
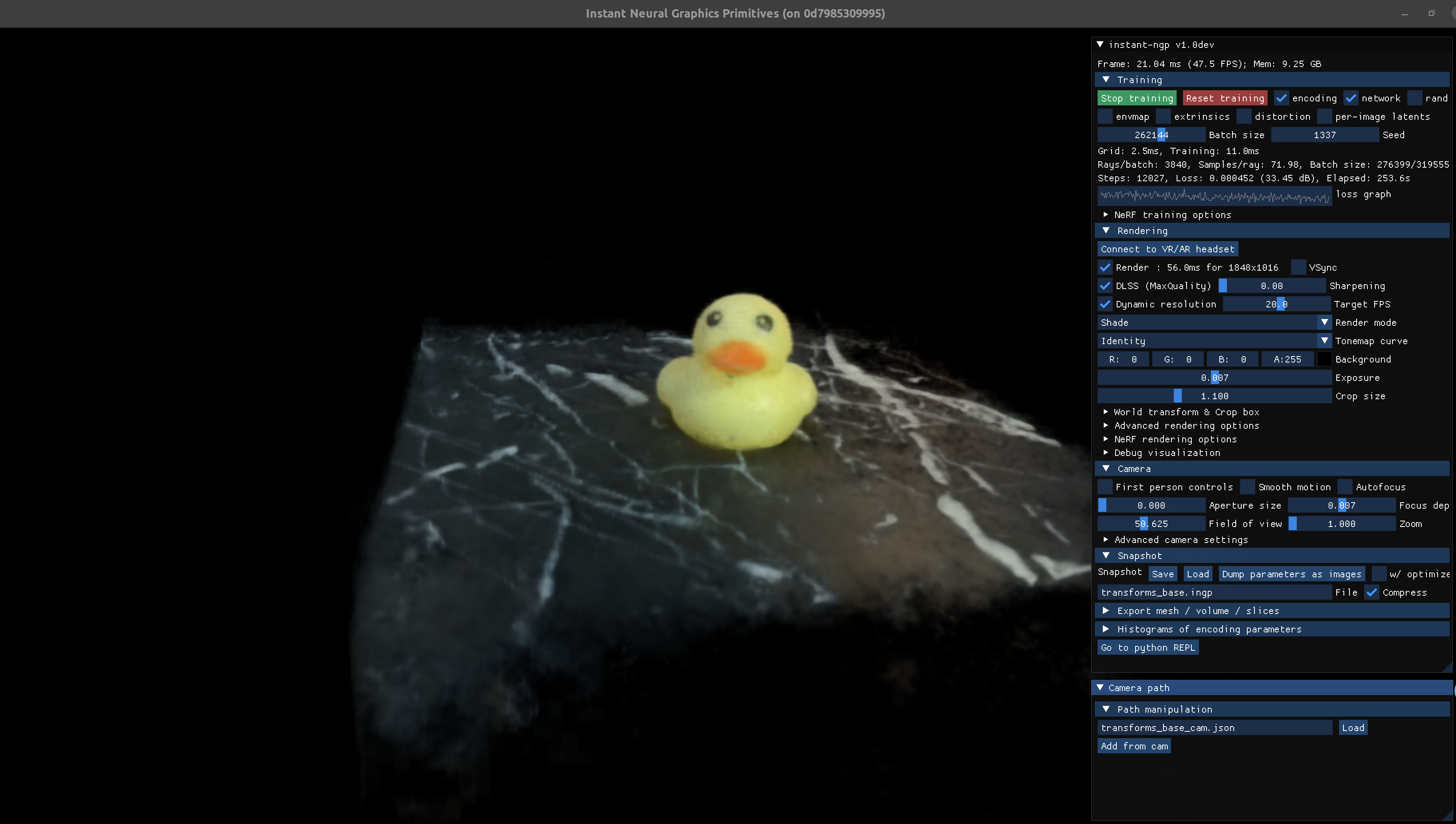
下图是 Instant-NGP 实验:
Reference¶
- nerf-learn
- NeRF 开篇论文解读 NeRF
- 【较真系列】讲人话 -NeRF 全解(原理 + 代码 + 公式)
- https://cloud.baidu.com/article/2741971