Vision Transformer¶
约 1497 个字 128 行代码 3 张图片 预计阅读时间 7 分钟
Abstract
- Google 首次 将 Transformer 应用到视觉上,即 ViT。
- 参考:
Vit 模型介绍 ¶

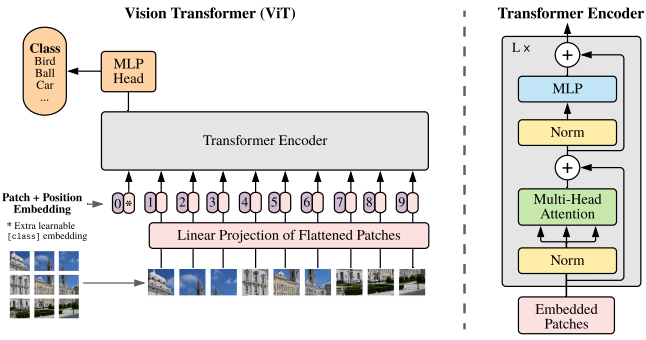
- 在 CV 中,卷积架构仍占主导地位,受 NLP 的启发,尝试将 Attention + CNN 或 Attention 替换 CNN components(保持 CNN 的整体结构
) 。 - 通过 Transformer 的放缩 / 扩展,尝试将 Transformer 直接应用于图像,为此,我们将图像拆分为块 (patch),并将这些图像块的线性嵌入序列作为 Transformer 的输入。图像块 (patches) 的处理方式同 NLP 的标记 (tokens) ( 故经过线性嵌入后又叫 patch token)。我们以有监督方式训练图像分类模型。
- Vit 证明不需要完全依赖 CNNs,直接应用于图像块序列(sequences of images patches)的纯 Transformer 可以很好地执行图像分类的任务。当对大量数据进行预训练并迁移到多个中小型图像识别基准时,ViT 有更好的效果。
方法 ¶
图像块嵌入 ¶
- 标准 Transformer 使用 一维标记嵌入序列(Sequence of token embeddings) 作为输入。
- 为处理 2D 图像,将图像 \(x \in R^{H \times W \times C}\) reshape 为一个铺平的 2D patches 序列 \(x_p \in R^{N \times (P^2 \cdot C)}\)
- (H,W):为原始图像分辨率
- C:原始图像通道数
- (P,P):每个图像 patch 的分辨率
- 产生的图像 patch 数 \(N = \frac{HW}{P^2}\):Transformer 的有效输入序列长度
- Transformer 在其所有层中使用恒定的隐向量(latent vector)大小 D,将图像 patches 铺平,并使用可训练的线性投影(FC 层)将维度 \(P^2C\) 映射为 D 维,同时保持图像 patches 数 D 不变。
- 投影输出即为图像块嵌入,等同于 NLP 中的词嵌入。
PatchEmbed
class PatchEmbed(nn.Module):
""" Image to Patch Embedding """
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
# (H, W)
img_size = to_2tuple(img_size)
# (P, P)
patch_size = to_2tuple(patch_size)
# N = (H // P) * (W // P)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
# 可训练的线性投影 - 获取输入嵌入
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*
{self.img_size[1]})."
# (B, C, H, W) -> (B, D, (H//P), (W//P)) -> (B, D, N) -> (B, N, D)
# D=embed_dim=768, N=num_patches=(H//P)*(W//P)
# torch.flatten(input, start_dim=0, end_dim=-1) # 形参:展平的起始维度和结束维度
# 可见 Patch Embedding 操作 1 行代码 3 步到位
x = self.proj(x).flatten(2).transpose(1, 2)
return x
位置信息编码 ¶
- 位置嵌入 \(E_{pos} \in R^{(N+1) \times D}\) 被加入到图像块嵌入,以保留输入图像块之间的空间位置信息。
- 不同于 CNN,Transformer 需要位置嵌入来编码 patch tokens 的位置信息,这主要由于 self-attention 的扰动不变性(打乱 Sequence 中 tokens 的顺序并不会改变结果)
- 如果不加位置信息,模型就需要通过图像块的语义来学习拼图
- Vit 中提供的位置编码方案
- 无位置嵌入
- 1-D 位置嵌入 (1D-PE):考虑把 2-D 图像块视为 1-D 序列
- 2-D 位置嵌入 (2D-PE):考虑图像块的 2-D 位置 (x, y)
- 相对位置嵌入 (RPE):考虑图像块的相对位置
- 在输入 Transformer 编码器之前直接将图像块嵌入和位置嵌入相加
Transformer 编码器 ¶
- Encoder 由交替的多头自注意力层(MSA)和多层感知机块(MLP)构成。在每个块前应用层归一化(Layer Norm
) ,每个块后应用残差连接(Residual Connection)
MSA
```python class Attention(nn.Module): def init(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.): super().init()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
# 附带 dropout
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
```
- MSA 后跟一个 FFN,包含两个 FC 层,第一个 FC 将特征从维度 D 变换成 4D,第二个 FC 将维度 4D 恢复成 D,中间的非线性激活函数均采用 GeLU (Gaussian Error Linear Unit,高斯误差线性单元 ),实质上是一个 MLP ( 多层感知机与线性模型类似,区别在于 MLP 相对于 FC 层数增加且引入了非线性激活函数,例如 FC + GeLU + FC)
MLP
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
- 一个 Encoder block 包含一个 MSA 和一个 FFN,二者都有跳跃连接和层归一化操作构成 MSA block 和 MLP block
block
# Transformer Encoder Block
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
# 后接于 MHA 的 Layer Norm
self.norm1 = norm_layer(dim)
# MHA
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# 后接于 MLP 的 Layer Norm
self.norm2 = norm_layer(dim)
# 隐藏层维度
mlp_hidden_dim = int(dim * mlp_ratio)
# MLP
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
# MHA + Add & Layer Norm
x = x + self.drop_path(self.attn(self.norm1(x)))
# MLP + Add & Layer Norm
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
- 集合了类别向量、图像块嵌入和位置编码为一体的输入嵌入向量后,即可馈入 Transformer Encoder。ViT 类似于 CNN,不断前向通过由 Transformer Encoder Blocks 串行堆叠构成的 Transformer Encoder,最后 提取可学习的类别嵌入向量 —— class token 对应的特征用于 图像分类。
归纳偏置与混合架构 ¶
归纳偏置 ¶
- ViT 的图像特定归纳偏执比 CNN 少很多。
- 在 CNN 中,局部性、二维邻域结构和平移等效性存在于整个模型的每一层中。
- 在 ViT 中,只有 MLP 层是局部和平移等变的,因为自注意力层都是全局的。
- 二维邻域结构:在模型开始时通过将图像切分成块,并在微调时调整不同分辨率图像的位置嵌入。
- 初始化时的位置嵌入不携带有关图像块的 2D 位置的信息,图像块之间的所有空间关系都必须从头开始学习。
混合架构 ¶
- 混合架构:作为原始图像块的替代方案,输入序列可由 CNN 的特征图构成。
- 图像块嵌入投影 E 被用在经 CNN 特征提取的块而非原始输入图像块。块的空间尺寸为 1x1,这表示输入序列是通过简单地将特征图的空间维度铺平并投影到 Transformer 维度获得。
微调及更高分辨率 ¶
- 在大型数据集上预训练 ViT,并对(更小的)下游任务进行微调。为此,移除了预训练的预测头部,换为一个零值初始化的 DxK 前馈层 / 全连接层,其中 K 是下游任务的类别数。
- 用比预训练时更高的图像分辨率进行微调通常效率更高。当提供更高分辨率的图像时,需保持图像 patchs 大小相同,此时有效图像 patchs 数变多,从而有效序列长度会更长。
- ViT 可以处理任意序列长度,但预训练的位置嵌入不再有意义,因此根据它们在原图中的位置,对预训练的位置嵌入执行 2D 插值,以扩展到微调尺寸。
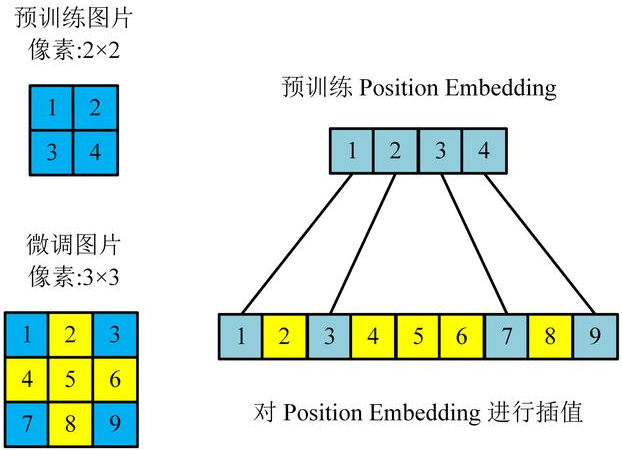
resize_pos_embed
def resize_pos_embed(posemb, posemb_new):
# Rescale the grid of position embeddings when loading from state_dict. Adapted from
# https://github.com/google-research/vision_transformer/blob/00883dd691c63a6830751563748663526e811cee/vit_jax/checkpoint.py#L224
_logger.info('Resized position embedding: %s to %s', posemb.shape, posemb_new.shape)
ntok_new = posemb_new.shape[1]
# 除去 class token 的 pos_embed
posemb_tok, posemb_grid = posemb[:, :1], posemb[0, 1:]
ntok_new -= 1
gs_old = int(math.sqrt(len(posemb_grid)))
gs_new = int(math.sqrt(ntok_new))
_logger.info('Position embedding grid-size from %s to %s', gs_old, gs_new)
# 把 pos_embed 变换到 2-D 维度再进行插值
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
posemb_grid = F.interpolate(posemb_grid, size=(gs_new, gs_new), mode='bilinear')
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_new * gs_new, -1)
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
return posemb
- 但这种情形会造成性能损失,可通过微调模型解决。
超参数 ¶
- Layers:Transformer Encoder Blocks 的数量
- Hidden Size D:隐藏层特征大小,在各 Encoder Block 保持一致
- MLP Size:MLP 特征大小,通常设为 4D
- Heads:MSA 的头数
- Patch Size:模型输入的 Patch size,ViT 中有两种设置:14x14 和 16x16