Transformer¶
约 2243 个字 84 行代码 18 张图片 预计阅读时间 9 分钟
Abstract
- 《Attention is all you need》这是谷歌团队在 2017 年发表的论文,也是首次提出 Transformer。
- 直接基于 Self-Attention 结构,取代了之前 NLP 任务中常用的 RNN 神经网络结构。
- 与 RNN 这类神经网络结构相比,Transformer 一个巨大的优点是:** 模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理输入序列。
整体架构 ¶

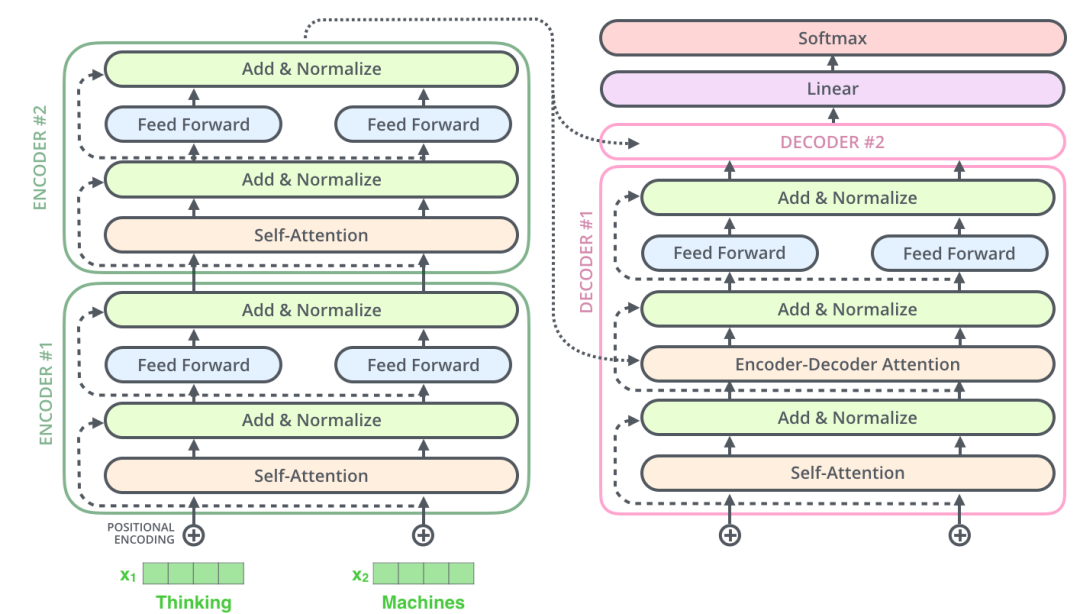
transformer 总体为一个编码组件、解码组件以及二者之间连接。

编码部分和解码部分都为编码器、解码器的堆叠,最后一层编码器的输出是各个解码器的输入之一。第一个编码器的输入为单词的嵌入向量,后面编码器输入为前一层的输出。
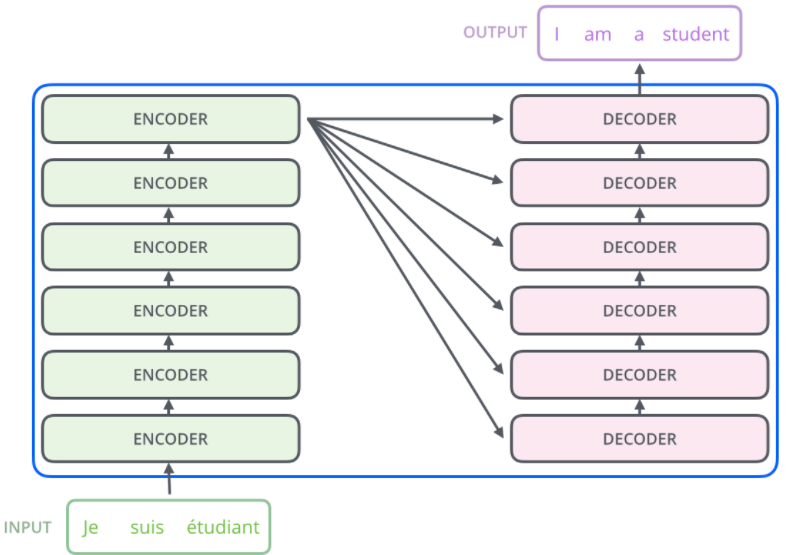
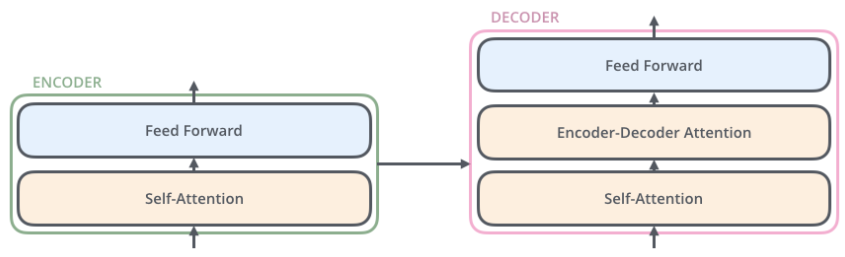
编码器均由两个子层组成:self-attention 与 feed forward neural network。self-attention 用于帮助编码器在编码特定单词时查看输入中的其他单词。解码器也有这两个子层,中间有一个注意力层,帮助解码器查看输入句子的相关部分。
输入处理 ¶
词向量 ¶
- 和常见的 NLP 任务一样,首先会使用词嵌入算法(embedding algorithm
) ,将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般为 256 或 512 维。 - 输入序列每个单词被转化成词向量表示还将加上位置向量来得到该词的最终向量表示。
位置向量 ¶
- 首先为什么需要位置编码?我们对于 RNN 在处理文本时,由于天然的顺序输入,顺序处理,当前输出要等上一步输出处理完后才能进行,因此不会造成文本的字词在顺序上或者先后关系出现问题。
- 但对于 Transformer 来说,由于其在处理时是并行执行,虽然加快了速度,但是忽略了词字之间的前后关系或者先后顺序。同时 Transformer 基于 Self-Attention 机制,而 self-attention 不能获取字词的位置信息,即使打乱一句话中字词的位置,每个词还是能与其他词之间计算出 attention 值,因此我们需要为每一个词向量添加位置编码。
- Transformer 模型对每个输入的词向量都加上了一个位置向量。这些向量有助于确定每个单词的位置特征,或者句子中不同单词之间的距离特征。词向量加上位置向量背后的直觉:将这些表示位置的向量添加到词向量中,得到的新向量,可以为模型提供更多有意义的信息,比如词的位置,词之间的距离等。
那么带有位置编码信息的向量到底遵循什么模式?原始论文中给出的设计表达式为:
上面表达式中的 \(pos\) 代表词的位置,\(d_{model}\) 代表位置向量的维度,\(i \in [0, d_{model})\) 代表位置 \(d_{model}\) 维位置向量第 \(i\) 维。于是根据上述公式,我们可以得到第 \(pos\) 位置的 \(d_{model}\) 维位置向量。在下图中,我们画出了一种位置向量在第 4、5、6、7 维度、不同位置的的数值大小。横坐标表示位置下标,纵坐标表示数值大小。
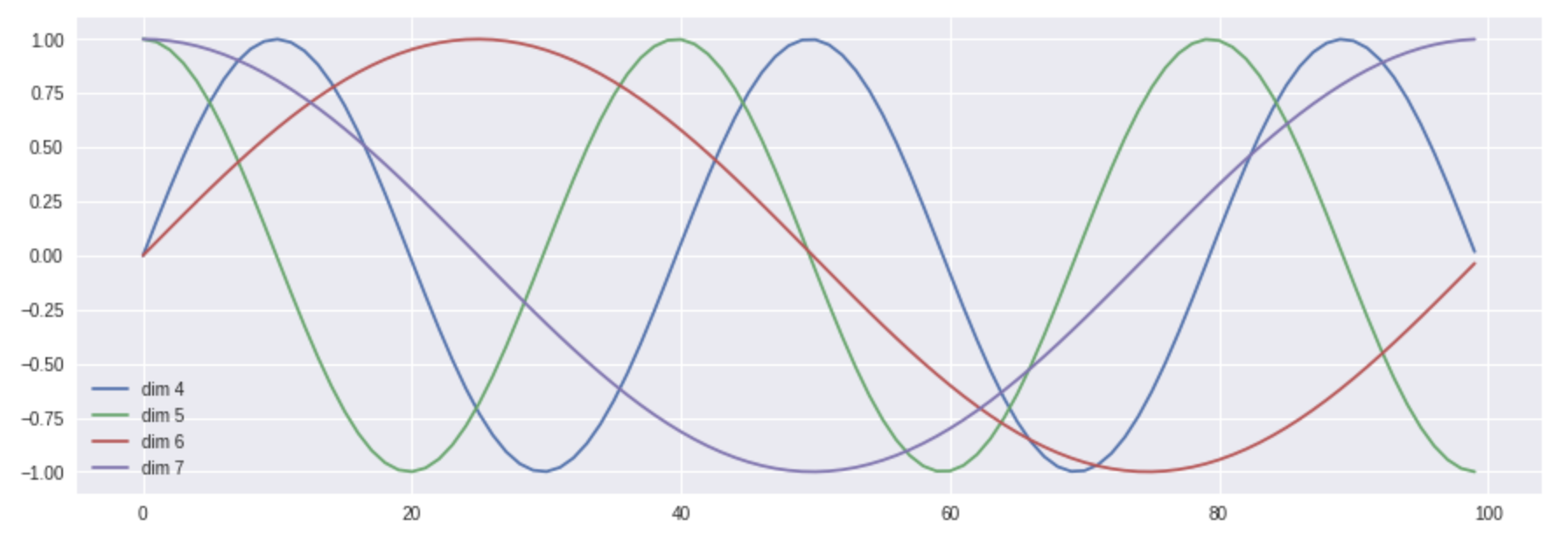
当然,上述公式不是唯一生成位置编码向量的方法。但这种方法的优点是:可以扩展到未知的序列长度。例如:当我们的模型需要翻译一个句子,而这个句子的长度大于训练集中所有句子的长度,这时,这种位置编码的方法也可以生成一样长的位置编码向量。
编码器 ¶
编码部分的输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第 1 层编码器,第 1 层编码器输出的同样是一个向量序列,再接着送入下一层编码器:第 1 层编码器的输入是融合位置向量的词向量,更上层编码器的输入则是上一层编码器的输出。
各个词向量均进入编码器的两个子层,self-attention 层中各个词向量的路径具有一定关联,而 FFNN 层中各个词向量参与的计算过程独立。

self-attention 使得模型在处理一个词向量时,能够将其与相关的词关联起来,以更好地对该词向量编码。RNN 通过维护隐藏状态以将先前处理的词向量同当前词向量合并,transformer 则使用 self-attention 将对相关词的“理解”融入当前处理的词。
Self-Attention 层 ¶
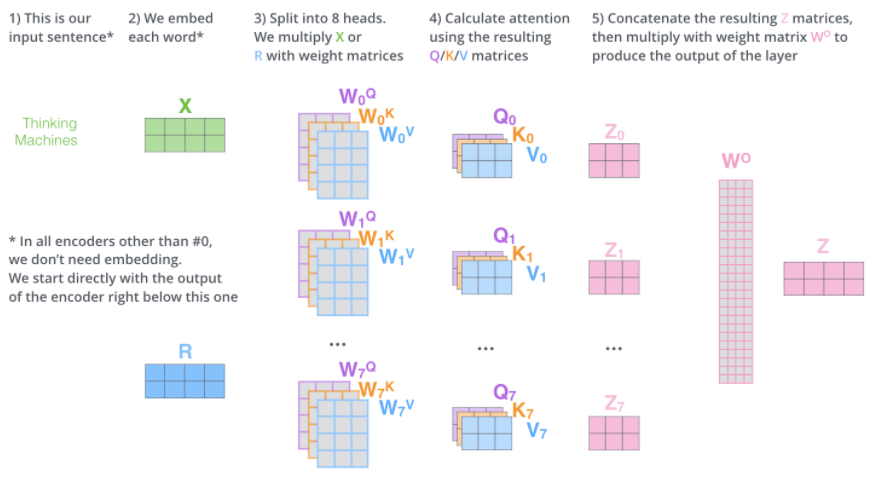
- 为每个词向量创建三个向量:
Query、Key、Value。这三个向量是通过将每个词向量乘以三个带训练的矩阵创建的(对后面的编码器,则是上一个编码器的输出乘以三个新的待训练矩阵) 。
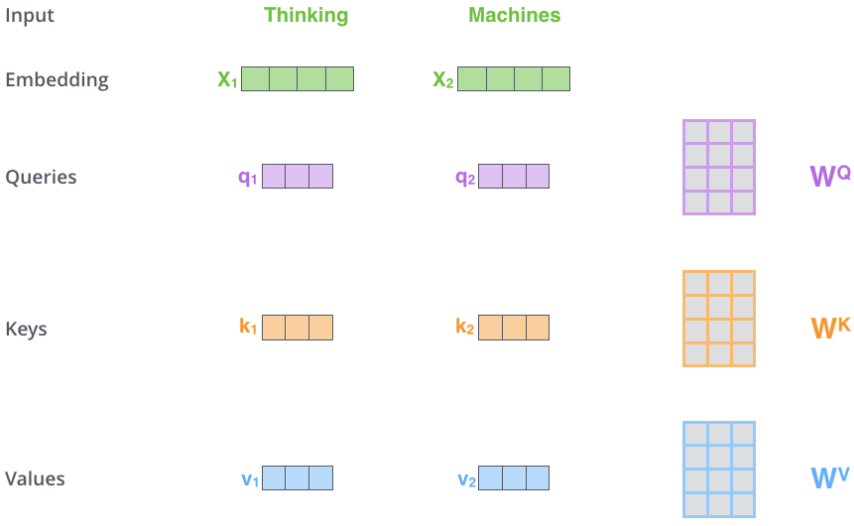
-
计算当前词向量与输入句子所有词向量的分数,分数会决定将多少注意力放在这些词上。分数通过将当前词向量对应的
Query向量与各个单词的key向量点积得到,第一个分数是q1与k1点积,第二个分数是q1与k2点积,以此类推。 -
将分数除以
Query向量长度的平方根。此步骤提高了梯度的稳定性。 - 通过
softmax将分数归一化。 - 归一化的得分与各个单词的
Value向量相乘,此做法的直觉是保持想要关注的单词的值不变,而且消除不相关的单词,即对各个单词的Value向量加权。 - 对所有加权后的
Value向量求和,即为当前词向量在self-attention层的输出。

上述过程的矩阵形式为:

多头注意力 ¶
进一步优化 Self-attention:使用 multi-headed attention。提高了模型关注不同位置的能力,为注意力层提供了多个表示子空间(representation subspaces)—— 可以有多组 Query、Key、Value 权重矩阵,每一组都是随机初始化,因此训练完成后每一组都可以将输入投射到不同的子空间,具体可以类比 CNN 中的多个卷积核。
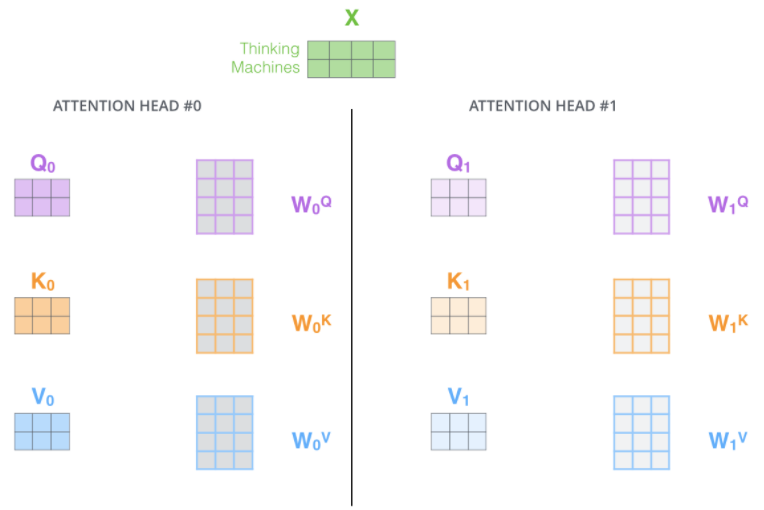
最终将得到多个当前词向量在 self-attention 下的输出向量,即输入句子经过 self-attention 后,将有多个输出矩阵。
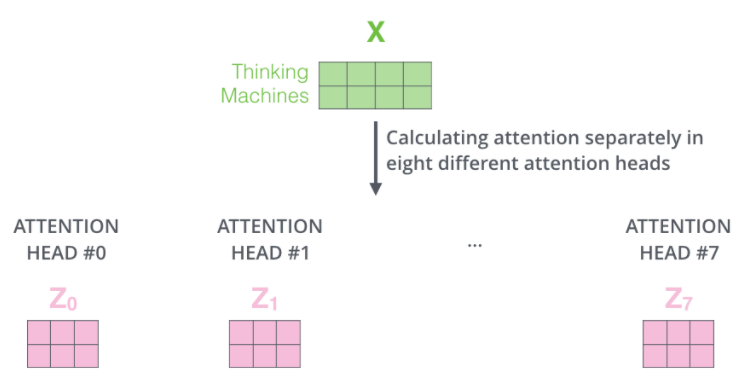
由于 FFNN 子层需要一个矩阵(每个单词由一个向量表示)作为输入,因此需要将以上输出矩阵与一个额外的待训练权重矩阵相乘。
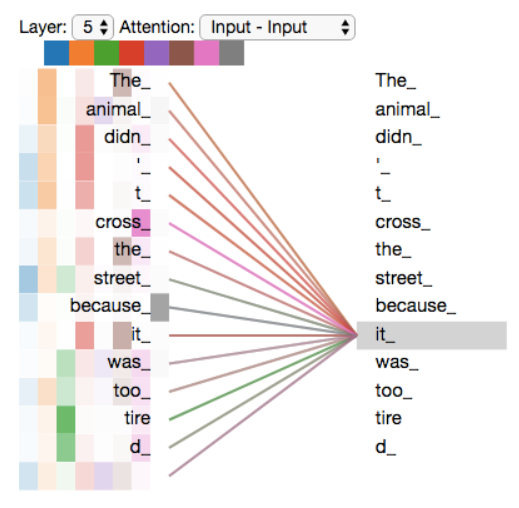
一个多头注意力的例子:
Attention 代码实例 ¶
张量的第 1 维是 batch size,第 2 维是句子长度。
class MultiheadAttention(nn.Module):
# n_heads:多头注意力的数量
# hid_dim:每个词输出的向量维度
def __init__(self, hid_dim, n_heads, dropout):
super(MultiheadAttention, self).__init__()
self.hid_dim = hid_dim
self.n_heads = n_heads
# 强制 hid_dim 必须整除 h
assert hid_dim % n_heads == 0
# 定义 W_q 矩阵
self.w_q = nn.Linear(hid_dim, hid_dim)
# 定义 W_k 矩阵
self.w_k = nn.Linear(hid_dim, hid_dim)
# 定义 W_v 矩阵
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
self.do = nn.Dropout(dropout)
# 缩放
self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads]))
def forward(self, query, key, value, mask=None):
# 注意 Q,K,V的在句子长度这一个维度的数值可以一样,可以不一样。
# K: [64,10,300], 假设batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维
# V: [64,10,300], 假设batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维
# Q: [64,12,300], 假设batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
bsz = query.shape[0]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
# 这里把 K Q V 矩阵拆分为多组注意力
# 最后一维就是是用 self.hid_dim // self.n_heads 来得到的,表示每组注意力的向量长度, 每个 head 的向量长度是:300/6=50
# 64 表示 batch size,6 表示有 6组注意力,10 表示有 10 词,50 表示每组注意力的词的向量长度
# K: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]
# V: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]
# Q: [64,12,300] 拆分多组注意力 -> [64,12,6,50] 转置得到 -> [64,6,12,50]
# 转置是为了把注意力的数量 6 放到前面,把 10 和 50 放到后面,方便下面计算
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
# 第 1 步:Q 乘以 K的转置,除以scale
# [64,6,12,50] * [64,6,50,10] = [64,6,12,10]
# attention:[64,6,12,10]
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# 如果 mask 不为空,那么就把 mask 为 0 的位置的 attention 分数设置为 -1e10,这里用“0”来指示哪些位置的词向量不能被attention到,比如padding位置,当然也可以用“1”或者其他数字来指示,主要设计下面2行代码的改动。
if mask is not None:
attention = attention.masked_fill(mask == 0, -1e10)
# 第 2 步:计算上一步结果的 softmax,再经过 dropout,得到 attention。
# 注意,这里是对最后一维做 softmax,也就是在输入序列的维度做 softmax
# attention: [64,6,12,10]
attention = self.do(torch.softmax(attention, dim=-1))
# 第三步,attention结果与V相乘,得到多头注意力的结果
# [64,6,12,10] * [64,6,10,50] = [64,6,12,50]
# x: [64,6,12,50]
x = torch.matmul(attention, V)
# 因为 query 有 12 个词,所以把 12 放到前面,把 50 和 6 放到后面,方便下面拼接多组的结果
# x: [64,6,12,50] 转置-> [64,12,6,50]
x = x.permute(0, 2, 1, 3).contiguous()
# 这里的矩阵转换就是:把多组注意力的结果拼接起来
# 最终结果就是 [64,12,300]
# x: [64,12,6,50] -> [64,12,300]
x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
x = self.fc(x)
return x
# batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
query = torch.rand(64, 12, 300)
# batch_size 为 64,有 12 个词,每个词的 Key 向量是 300 维
key = torch.rand(64, 10, 300)
# batch_size 为 64,有 10 个词,每个词的 Value 向量是 300 维
value = torch.rand(64, 10, 300)
attention = MultiheadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
## output: torch.Size([64, 12, 300])
print(output.shape)
残差连接 ¶
编码器中每个子层都进行残差连接,并归一化。
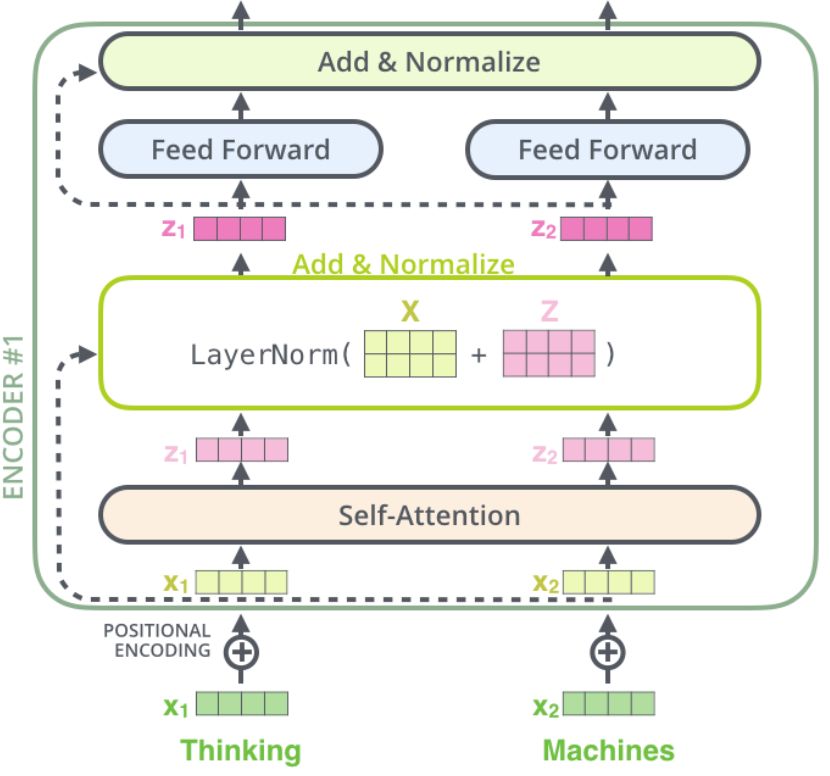
将 Self-Attention 层的层标准化(layer-normalization)和涉及的向量计算细节都进行可视化,如下所示:

编码器和和解码器的子层里面都有层标准化(layer-normalization
解码器 ¶
编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量,这组序列向量会作为解码器的 K、V 输入,其中 K=V= 解码器输出的序列向量表示。这些注意力向量将会输入到每个解码器的 Encoder-Decoder Attention 层,这有助于解码器把注意力集中到输入序列的合适位置,如下图所示。
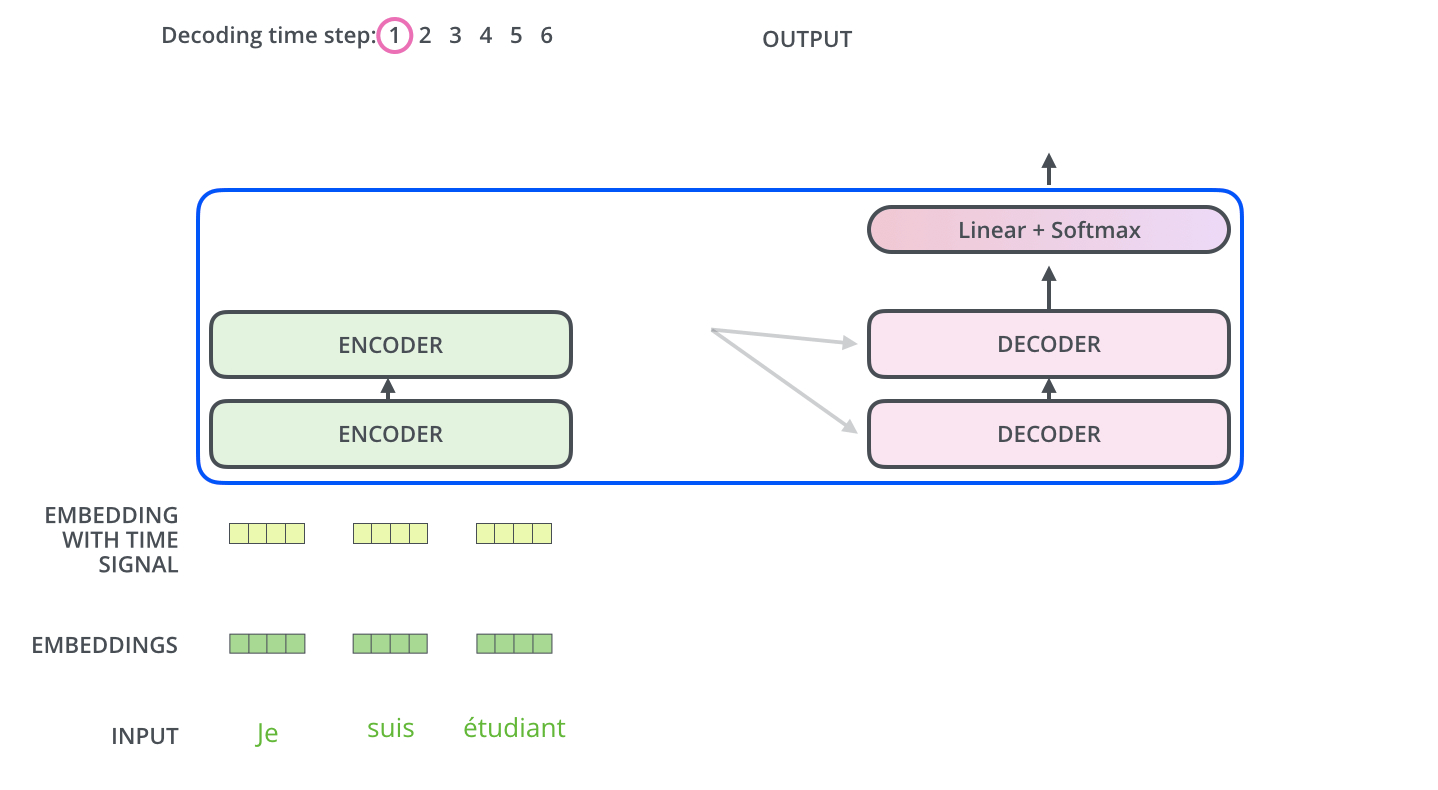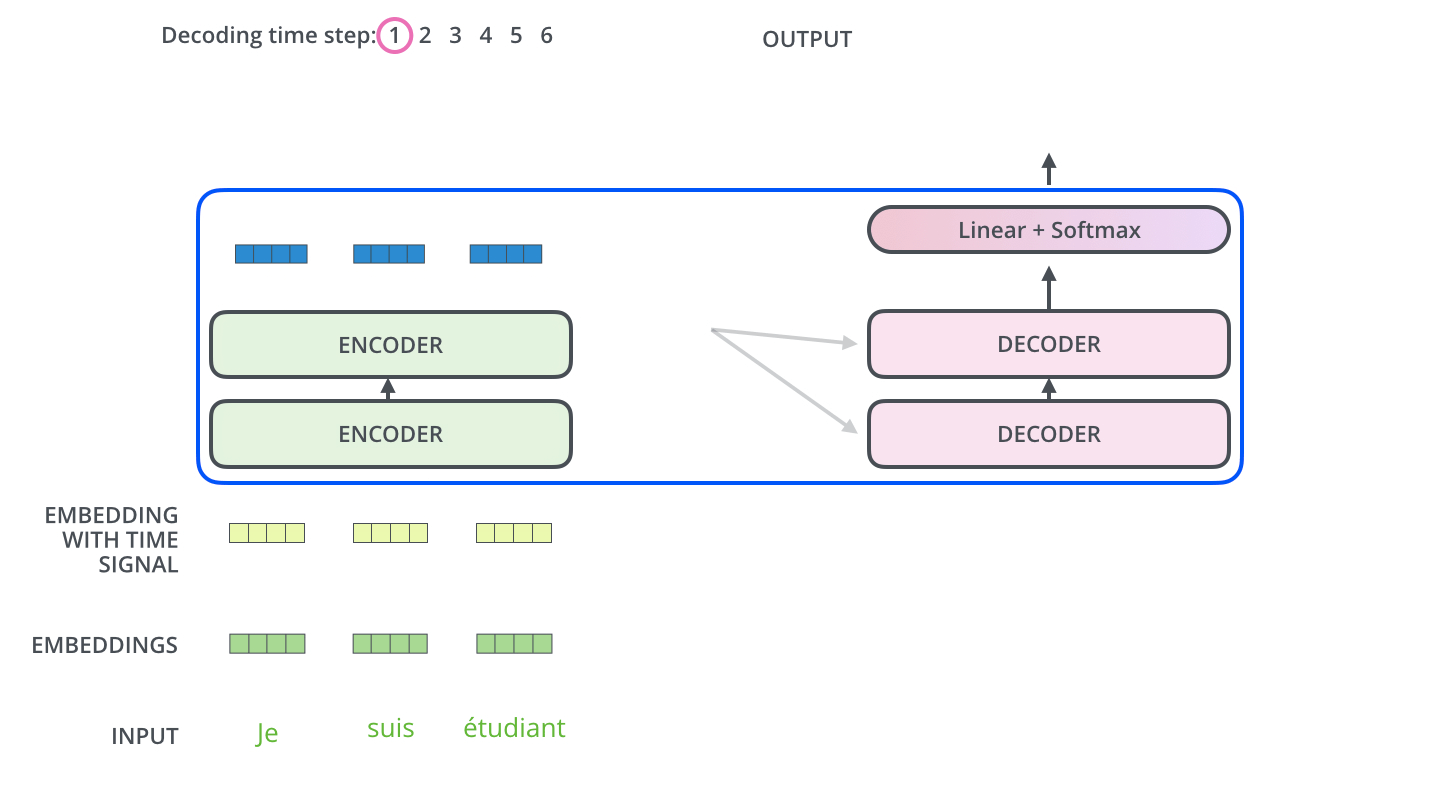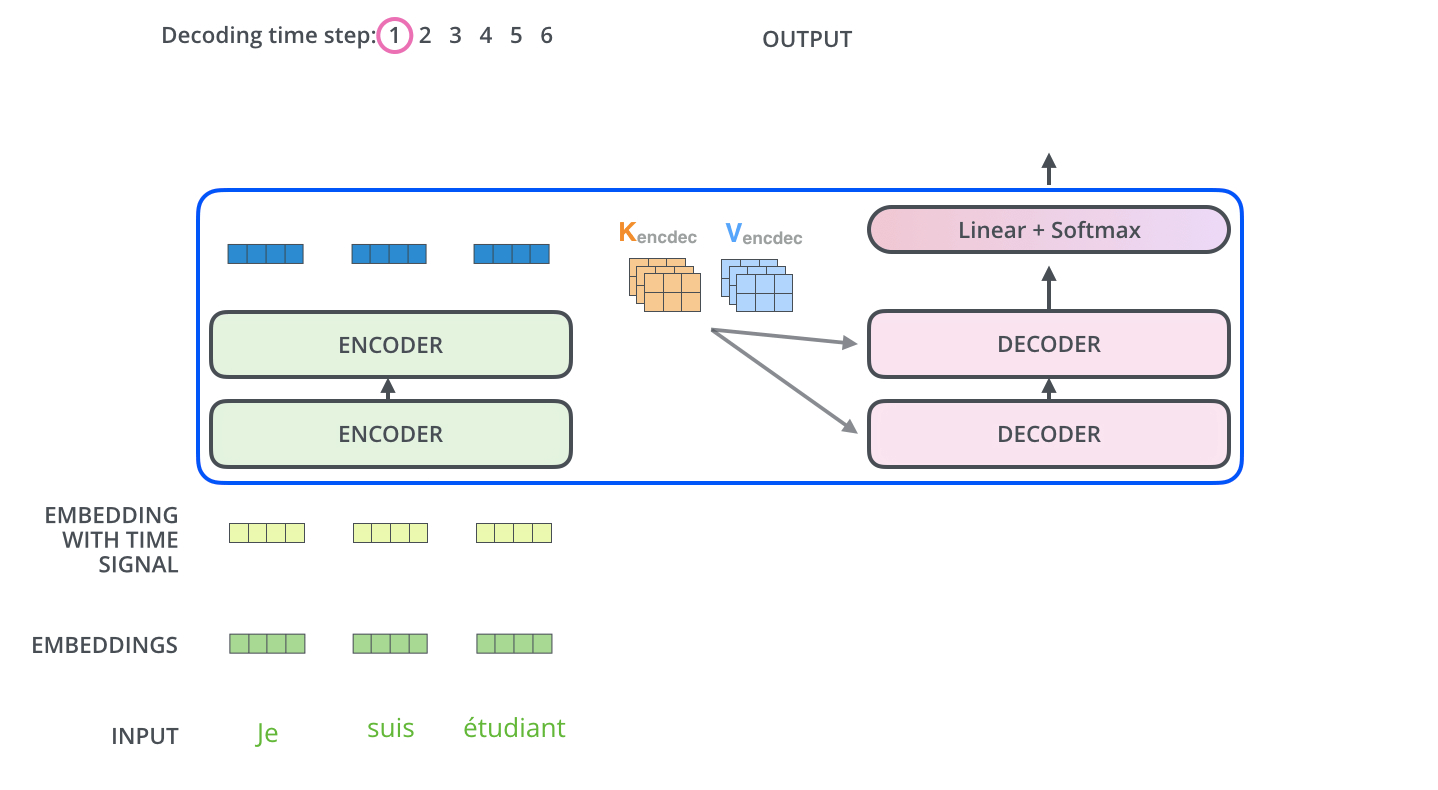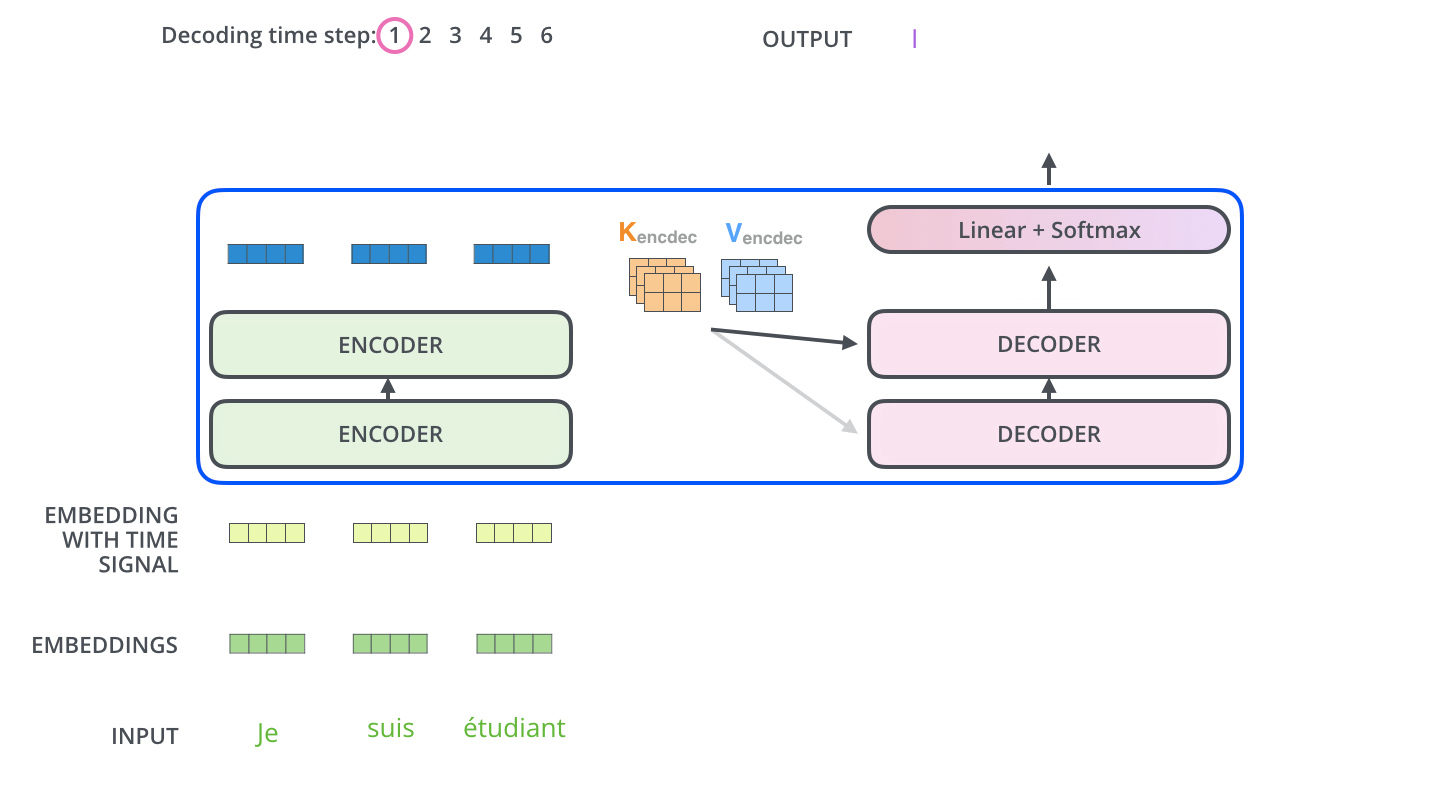
解码(decoding)阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译

解码器中的 Self Attention 层,和编码器中的 Self Attention 层的区别:
- 在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置(将 attention score 设置成 -inf
) 。 - 解码器 Attention 层是使用前一层的输出来构造 Query 矩阵,而 Key 矩阵和 Value 矩阵来自于编码器最终的输出。