OpenMP 基础 ¶
约 1763 个字 38 行代码 1 张图片 预计阅读时间 6 分钟
什么是 OpenMP ¶
- Open Multi-Processing
- OpenMP 是一个应用程序接口(API
) ,可以简单理解为一个库 - 支持 C、C++ 和 Fortran
- 支持多种指令集和操作系统
OpenMP 的适用范围:多线程、共享内存
- 共享存储体系结构上的一个并行编程模型
- 适用于 SMP(Symmetric Multi-Processor)共享内存多处理系统和多核处理器体系结构
三类主要 API(表现为编译制导指令,但实际上仍为 API
传统上,我们利用 OpenMP 进行单机器 CPU 优化(可跨处理器
并行性 ¶
进程和线程 ¶
- 进程
- 每个进程有自己独立的地址空间
- CPU 在进程之间切换需要进行上下文切换
- 线程
- 一个进程下的线程共享地址空间
- CPU 在线程之间切换开销小
线程的硬件调度 ¶
- 硬件和操作系统会自动将线程调度到 CPU 核心运行
- 当线程数目超过核心数,会出现多个线程抢占一个 CPU 核心,导致性能下降
- 超线程(hyper-threading)将单个 CPU 物理核心抽象为多个(目前通常为 2 个)逻辑核心,共享物理核心的计算资源
硬件的内存模型 ¶
- CPU 核心在主存之上有 L1,L2,L3 多级缓存
- L1,L2 缓存是核心私有的
- 硬件和操作系统保证不同核心的缓存一致性(coherence)
- 被称为 cache coherence non-uniform memory access(ccNUMA)
- 缓存一致性会带来 False Sharing 的问题
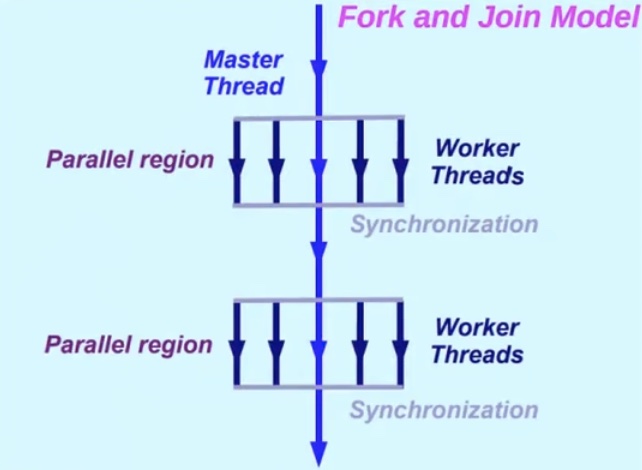
Fork-Join 模型 ¶
- 单线程(initial thread)开始执行
- 进入并行区(parallel region)开始并行执行
- 在并行区结尾进行同步和结束线程,继续单线程执行程序
OpenMP 编程 ¶
安装 ¶
- 含在 Ubuntu 提供的 build-essential 包中
编译使用 ¶
- 可以直接在编译语句添加
-fopenmp,如
- 如果用 cmake 构建项目,gcc 加入
-Wunknown-pragmas会在编译时报告没有处理的#pragma,可以用来检查是否有遗漏的 OpenMP 指令
find_package(OpenMP)
add_compile_options(-Wunknown-pragmas)
add_executable(hello src/hello.cpp)
target_link_libraries(hello OpenMP::OpenMP_CXX)
库函数 ¶
使用时要 #include <omp.h>,一些常用函数:
void omp_set_num_threads(int):设置并行区运行的线程数int omp_get_thread_num(void):获取当前线程号int omp_get_num_threads(void):获取总线程数double omp_get_wtime(void):获取时间,常用于计算线程内语句执行时间double opm_get_wtick(void):获得omp_get_wtime时间精度
OpenMP 会读取环境变量 OMP_NUM_THREADS 来决定创建的线程数
制导语句 ¶
- 同一类
openmp制导语句称为一种构造(construct) - 形式为
#pragma omp <directive> <clause> - 使用
{}标记作用的代码块 - 支持的从句
default(shared|none):指定默认shared:默认为共享变量none:无默认变量类型,每个变量都需要另外指定
shared(list):指定共享变量列表变量类型- 共享变量在内存中只有一份,所有线程都可以访问
- 请保证共享访问不会冲突
- 不特别指定并行区变量默认为 shared
private(list):指定私有变量列表- 每个线程生成一份与该私有变量同类型的数据对象
- 变量需要重新初始化
firstprivate(list)- 同 private
- 对变量根据祝线程中的数据进行初始化
lastprivate(list)- 同 private
- 执行最后一个循环的线程的私有数据取出赋值给主线程的变量
nowait:取消代码块结束的栅栏同步(barrier)collapse(n):应用于 n 重循环,合并(展开)循环并行- 注意循环之间是否有数据依赖
ordered:声明有潜在的顺序执行部分- 使用
#pragma omp ordered标记顺序执行代码(搭配使用) - ordered 区内的语句任意时刻仅由最多一个线程执行
- 使用
schedule(type [, chuck]):控制调度方式static:chunk 大小固定(默认 n/p)dynamic:动态调度,chunk 大小固定(默认 1)guided:chunk 大小动态递减runtime:由系统环境OMP_SCHEDULE决定
parallel 线程并行 ¶
使用 #pragma omp parallel 创建并行块来并行运行同一段程序:
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
#pragma omp parallel
{
int ID = omp_get_thread_num();
printf("thread #%d\n", ID);
}
}
for 循环并行 ¶
parallel 块内可以使用 #pragma omp for 来对 for 循环进行并行,相当于将循环拆成不同部分分配给多个线程
- 格式要求
- init-expr: 需要是
var=lb形式,类型也有限制 - test-expr: 限制为
var reational-opb或者b relational-opb var - incr-expr: 限制为
var=var +/- incr或者var=var +/- incr
- init-expr: 需要是
parallel 和 for 可以合起来写作一行 #pragma omp parallel for
if 条件并行 ¶
可以在制导语句后面加 if 子句来决定是否进行并行:
- 如果 x 不为 0 则分为四个线程执行块内内容
- 如果 x 为 0 则由主线程串行执行
reduction 执行过程 ¶
- fork 线程并分配任务
- 每一个线程定义一个私有变量
omp_private,同private - 各个线程执行计算
- 所有
omp_priv和omp_in一起顺序进行 reduction,写回原变量
同步构造 ¶
#pragma omp sections¶
- 将并行区内的代码块划分为多个
section分配执行 - 可以搭配
parallel合并为#pragma omp parallel sections构造 - 每个
section由一个线程执行- 线程数大于
section数目:部分线程空闲 - 线程数小于
section数目,部分线程分配多个section
- 线程数大于
#pragma omp barrier¶
- 在特定位置进行栅栏同步
- 每个并行块都含有隐式的 barrier,也就是在所有线程都结束后才能继续向下运行
在并行块内也可以利用
#pragma omp barrier来同步各线程,即所有线程都触碰到 barrier 时再继续 - 可以利用 nowait 子句来取消并行块结尾的隐式 barrier,避免同步产生的开销
#pragma omp single¶
- 某段代码单线程执行,带隐式同步(使用 nowait 去掉)
- single 用来序列化一段代码,即在一个进程中执行(处理非线程安全的代码,例如 IO)
#pragma omp master¶
- 采用主线程执行,无隐式同步
#pragma omp critical¶
- 某段代码线程互斥执行
#pragma omp atomic¶
- 单个特定格式的语句或语句组中某个变量进行原子操作
False Sharing¶
- 耗时增加 24%
- 不同核心对同一 cache line 的同时读写会造成严重的冲突,导致该级缓存失效
更多特性 ¶
任务构造 ¶
- 前述的构造都遵循 Fork-Join 模式,对任务类型有限制
- 任务(task)构造允许定义任务以及依赖关系,动态调度执行
- 即动态管理线程池(thread pool)和任务池(task pool)
向量化 ¶
- 将循环转换为 SIMD 循环
aligned用于列出内存对齐的指针safelen用于标记循环展开时的数据依赖- 编译器也自带向量化功能,例如 gcc
- -O3
- -ffast-math
- -fivopts
- -march=native
- -fopt-info-vec
- -fopt-info-vec-missed
GPU 支持 ¶
- 从 OpenMP API 4.0 开始支持 GPU 加速