Redis 数据类型 ¶
1. NoSQL¶
NoSQL(Not Only SQL ),意即不仅仅是 SQL, 泛指非关系型的数据库。Nosql 这个技术门类 , 早期就有人提出 , 发展至 2009 年趋势越发高涨。
1.1 单机 Mysql 时代 ¶

1.2 Memcached( 缓存 ) + Mysql + 垂直拆分(读写分离)¶
网站 80% 的情况都是在读,每次都要去查询数据库的话就十分的麻烦!所以说我们希望减轻数据库的压力,我们可以使用缓存来保证效率! 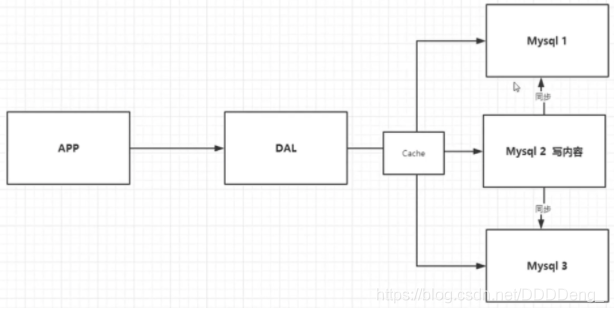
1.3 分库分表 + 水平拆分 + Mysql 集群 ¶
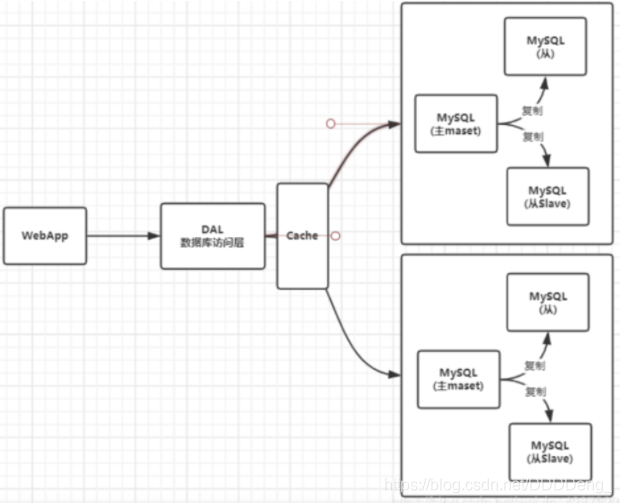
1.4 如今最近的年代 ¶
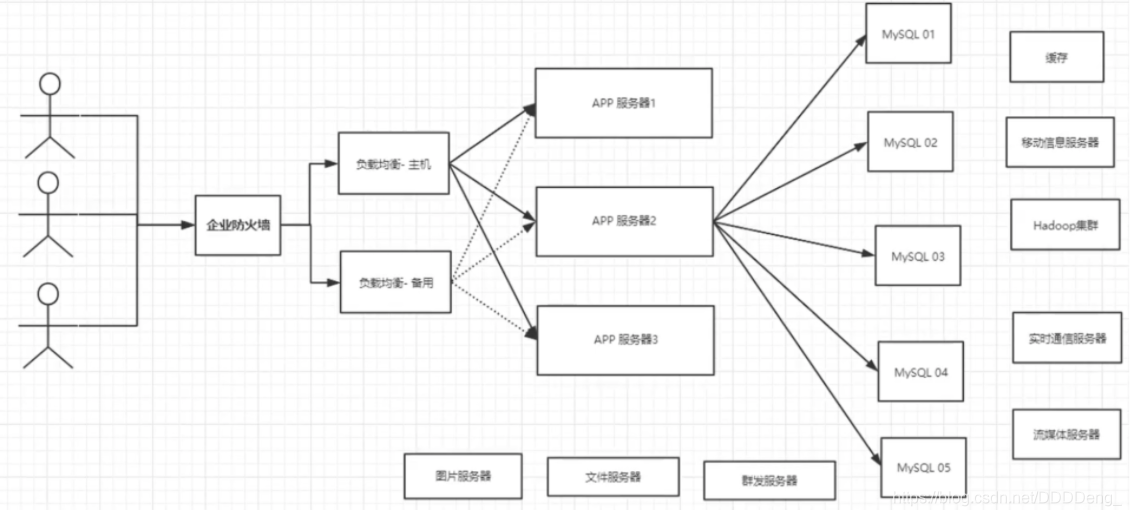
2. 为什么是 NoSQL ¶
NoSQL = Not Only SQL(不仅仅是 SQL)
Not Only Structured Query Language
关系型数据库:列 + 行,同一个表下数据的结构是一样的。
非关系型数据库:数据存储没有固定的格式,并且可以进行横向扩展。
NoSQL 泛指非关系型数据库,随着 web2.0 互联网的诞生,传统的关系型数据库很难对付 web2.0 时代!尤其是超大规模的高并发的社区,暴露出来很多难以克服的问题,NoSQL 在当今大数据环境下发展的十分迅速,Redis 是发展最快的。
随着互联网网站的兴起,传统的关系数据库在应付动态网站,特别是超大规模和高并发的纯动态网站已经显得力不从心,暴露了很多难以克服的问题。如商城网站中对商品数据频繁查询、对热搜商品的排行统计、订单超时问题、以及微信朋友圈(音频,视频)存储等相关使用传统的关系型数据库实现就显得非常复杂,虽然能实现相应功能但是在性能上却不是那么乐观。nosql 这个技术门类的出现,更好的解决了这些问题,它告诉了世界不仅仅是 sql。
了解:3V + 3 高
大数据时代的 3V :主要是描述问题的
- 海量 Velume
- 多样 Variety
- 实时 Velocity
大数据时代的 3 高 : 主要是对程序的要求
- 高并发
- 高可扩
- 高性能
3. NoSQL 的四大分类 ¶
3.1 键值 (Key-Value) 存储数据库 ¶
# 1.说明:
- 这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。
# 2.特点
- Key/value模型对于IT系统来说的优势在于简单、易部署。
- 但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。
# 3.相关产品
- Tokyo Cabinet/Tyrant,
- Redis
- SSDB
- Voldemort
- Oracle BDB
3.2 列存储数据库 ¶
# 1.说明
- 这部分数据库通常是用来应对分布式存储的海量数据。
# 2.特点
- 键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。
# 3.相关产品
- Cassandra、HBase、Riak.
3.3 文档型数据库 ¶
# 1.说明
- 文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高
# 2.特点
- 以文档形式存储
# 3.相关产品
- MongoDB、CouchDB、 MongoDb(4.x). 国内也有文档型数据库SequoiaDB,已经开源。
3.4 图形 (Graph) 数据库 ¶
# 1.说明
- 图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。
- NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。
# 2.特点
# 3.相关产品
- Neo4J、InfoGrid、 Infinite Graph、
4. NoSQL 应用场景 ¶
- 数据模型比较简单
- 需要灵活性更强的 IT 系统
- 对数据库性能要求较高
- 不需要高度的数据一致性
5. 什么是 Redis ¶

Redis 开源 遵循 BSD 基于内存数据存储 被用于作为 数据库 缓存 消息中间件 redis 是一个内存型的数据库
6. Redis 特点 ¶
- Redis 是一个高性能 key/value 内存型数据库
- Redis 支持丰富的数据类型
- Redis 支持持久化
- Redis 单线程 , 单进程
单线程不一定比多线程慢,在 CPU 中,多线程需要跳转,而单线程不需要,减少了跳转的消耗,所以在某些场景里单线程可能比多线程快。
7. Ridis 安装 ¶
略
8. redis 常用命令 ¶
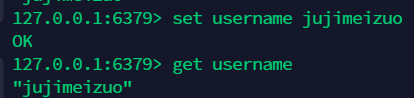
8.1 set get 命令,存值,取值 ¶
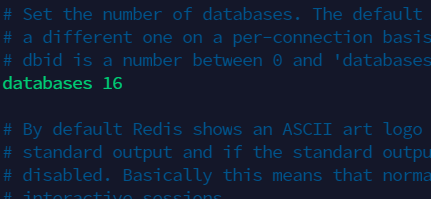
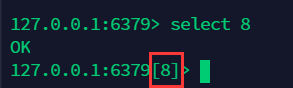
8.2 切换数据库,redis 默认有 16 个数据库,默认使用 0 号数据库,可以通过 select 切换 ¶
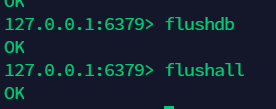
8.3 清空当前数据库:flushdb, 清空所有数据库:flushall¶
8.4 查询所有 key: keys* ¶
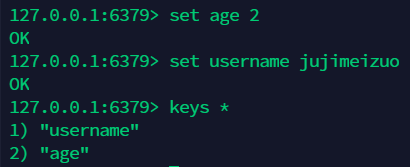
8.5 查询数据库的大小:dbsize¶

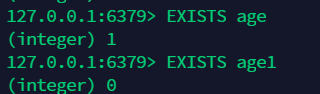
8.6 查看 key 是否存在:exists keyName, 存在返回 1,否则返回 0 ¶
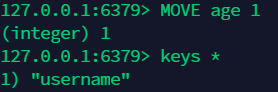
8.7 移除 Key: move keyName 1 ¶
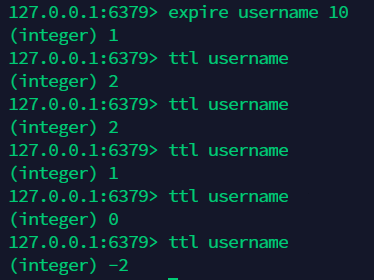
8.8 为 key 设置过期时间 : expire keyName timeout ¶

8.9 查看 key 的剩余存活时间:ttl keyName¶
8.10 查看 key 的类型:type keyName¶
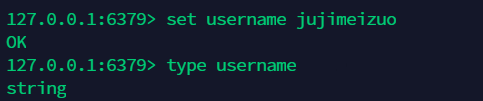
9. String 详解 ¶
| 命令 | 说明 |
| ------------------------- | ----------------------- |
| set | 设置一个key/value |
| get | 根据key获得对应的value |
| mset | 一次设置多个key value |
| mget | 一次获得多个key的value |
| getset | 获得原始key的值,同时设置新值 |
| strlen | 获得对应key存储value的长度 |
| append | 为对应key的value追加内容 |
| getrange 索引0开始 | 截取value的内容 |
| setex | 设置一个key存活的有效期(秒) |
| psetex | 设置一个key存活的有效期(毫秒) |
| setnx | 存在不做任何操作,不存在添加 |
| msetnx原子操作(只要有一个存在不做任何操作) | 可以同时设置多个key,只有有一个存在都不保存 |
| decr | 进行数值类型的-1操作 |
| decrby | 根据提供的数据进行减法操作 |
| Incr | 进行数值类型的+1操作 |
| incrby | 根据提供的数据进行加法操作 |
| Incrbyfloat | 根据提供的数据加入浮点数 |
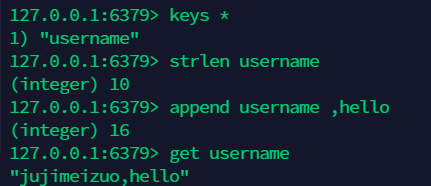
9.1 strlen: 求 value 的长度,append:追加 ¶
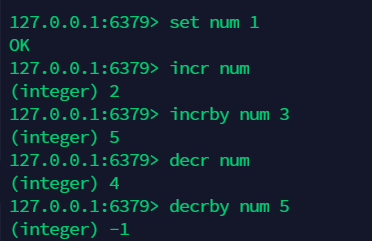
9.2 自增 , 自减操作:incr incrby decr decrby¶
9.3 字符串的范围操作:getrange,setrange¶
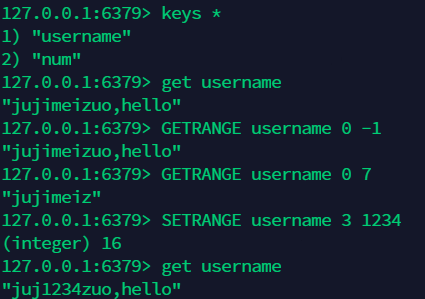
9.4 设置过期时间:setex(如果存在 Key 则覆盖,不存在则创建) ,setnx( 如果不存在就设置 ) ¶
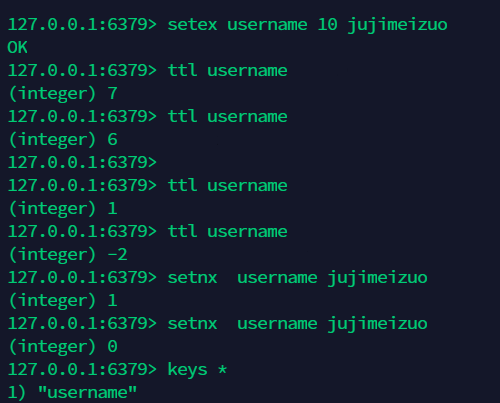
9.5 批量设置和获取值:mset,mget, msetnx( 操作为原子性,要么都成功,要么都失败 ) ¶
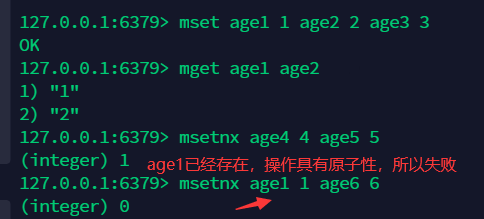
9.6 存取对象 ¶
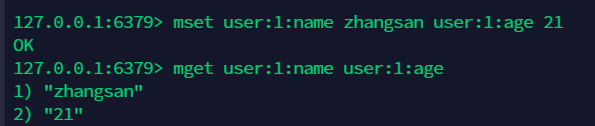
9.7 组合操作:getset 先获取再设置 , 如果不存在就返回 nil ¶
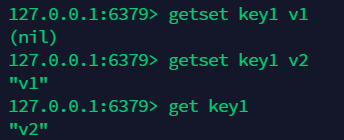
String 类似的使用场景:value 除了是我们的字符串还可以是我们的数字!
- 计数器
- 统计多单位的数量
- 粉丝数
- 对象缓存存储
10. list 详解 ¶
list 的命令都是 l 开头 ,list 列表 相当于 java 中 list 集合 特点 元素有序 且 可以重复
| 命令 | 说明 |
| ------- | --------------------- |
| lpush | 将某个值加入到一个key列表头部 |
| lpushx | 同lpush,但是必须要保证这个key存在 |
| rpush | 将某个值加入到一个key列表末尾 |
| rpushx | 同rpush,但是必须要保证这个key存在 |
| lpop | 返回和移除列表左边的第一个元素 |
| rpop | 返回和移除列表右边的第一个元素 |
| lrange | 获取某一个下标区间内的元素 |
| llen | 获取列表元素个数 |
| lset | 设置某一个指定索引的值(索引必须存在) |
| lindex | 获取某一个指定索引位置的元素 |
| lrem | 删除重复元素 |
| ltrim | 保留列表中特定区间内的元素 |
| linsert | 在某一个元素之前,之后插入新元素 |
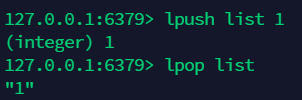
10.1 左插:lpush, 左删:lpop¶
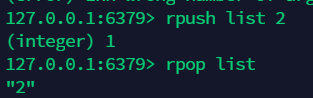
10.2 右插:rpush, 右删:rpop¶
10.3 获取列表元素:lrange¶
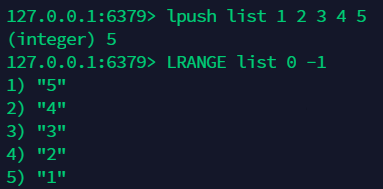
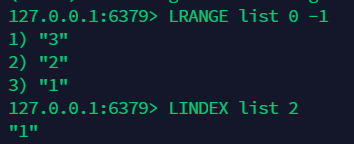
10.4 通过下标获取元素:lindex¶
10.5 获取列表长度:llen¶

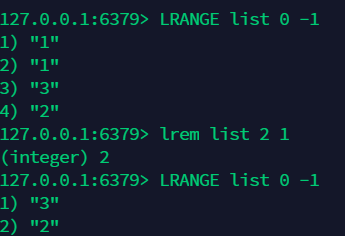
10.6 移除具体的值所在的键值对 :lrem 列表 移除几个 移除的具体 value ¶
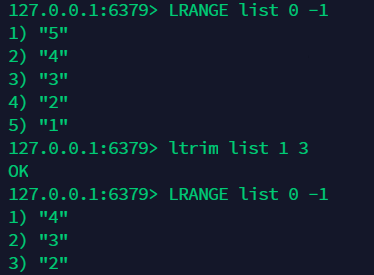
10.7 截取操作:ltrim 列表 截取的开始下标 截取的结束下标 ¶
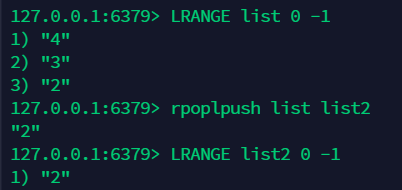
10.8 rpoplpush: 移除列表中的最后一个元素并将这个元素放到一个新的列表中 ¶
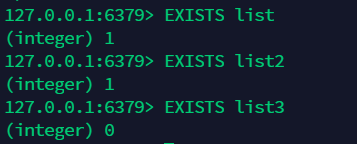
10.9 判断列表是否存在:EXISTS list¶
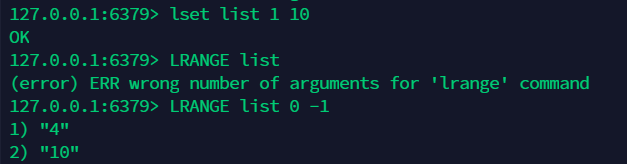
10.10 lset: 更新列表中指定下标的元素的 value, 前提是该下标必须有值,否则报错 ¶
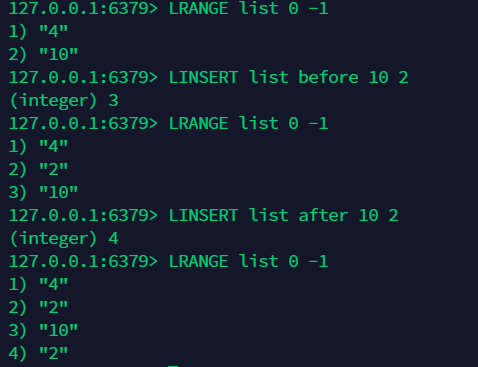
10.11 在列表中插入值:前插和后插:linsert¶
11. set 详解 ¶
set 是无序不重复集合,set 命令都是 s 开头 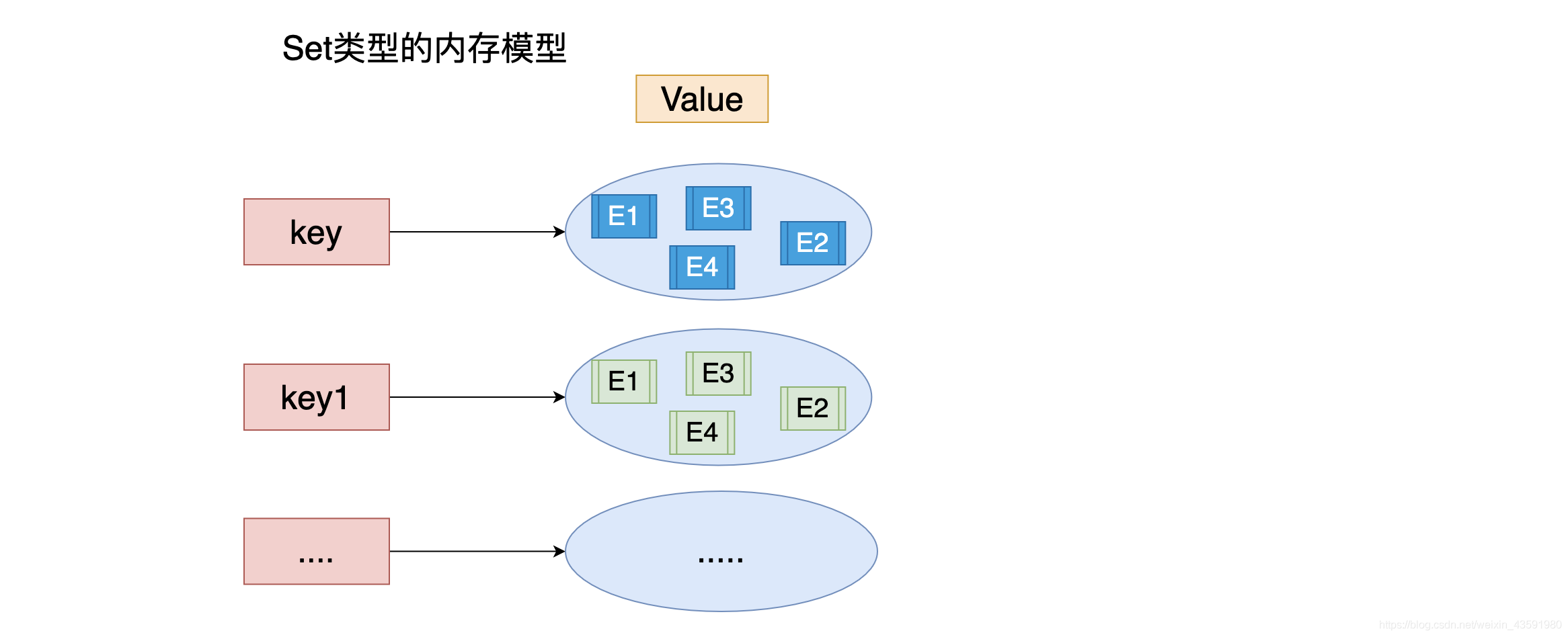
| 命令 | 说明 |
| ----------- | ------------------------- |
| sadd | 为集合添加元素 |
| smembers | 显示集合中所有元素 无序 |
| scard | 返回集合中元素的个数 |
| spop | 随机返回一个元素 并将元素在集合中删除 |
| smove | 从一个集合中向另一个集合移动元素 必须是同一种类型 |
| srem | 从集合中删除一个元素 |
| sismember | 判断一个集合中是否含有这个元素 |
| srandmember | 随机返回元素 |
| sdiff | 去掉第一个集合中其它集合含有的相同元素 |
| sinter | 求交集 |
| sunion | 求和集 |
11.1 添加:sadd¶

11.2 查看所有 : smembers ¶
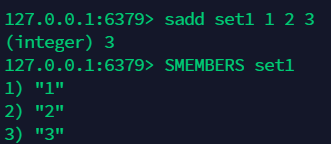
11.3 查询 set 的元素个数:scard¶
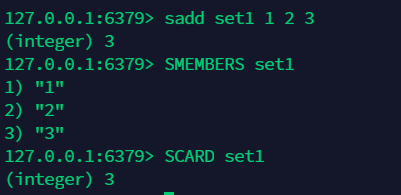
11.4 判断 set 中是否存在某元素:sismember¶
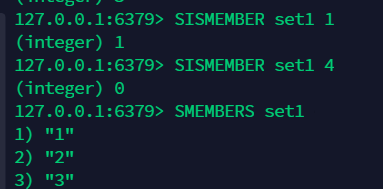
11.5 移除某个元素:srem¶
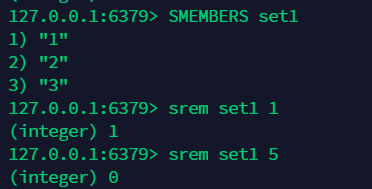
11.6 随机抽取一个元素:SRANDMEMBER¶
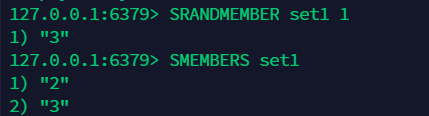
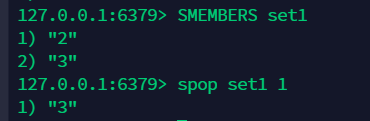
11.7 随机移除一个元素:spop¶
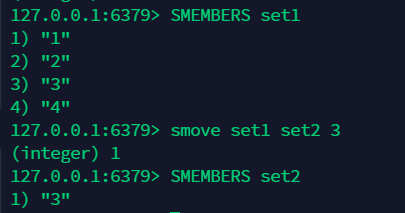
11.8 将一个集合中的元素移动到另一个集合中:smove¶
11.9 集合之间求交并补集:sinter sunite sdiff¶
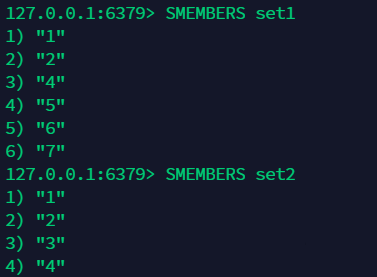
差集 sdiff ¶
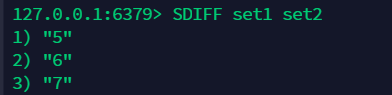
交集 sinter ¶
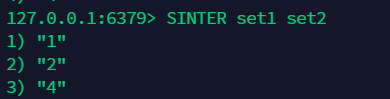
并集 sunion ¶
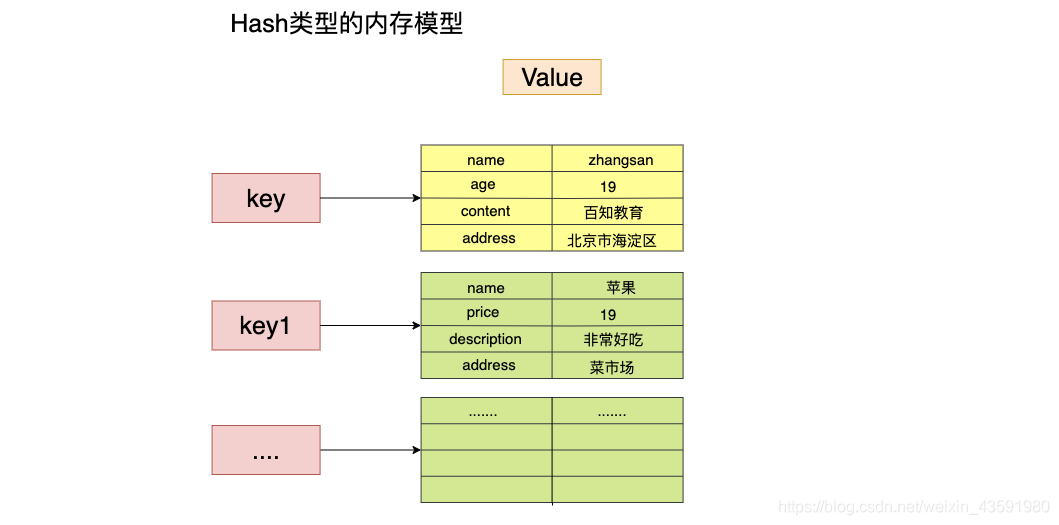
12. hash 详解 ¶
hash 的形式:key filed vlaue, 相当于 java 中的 map 集合 hash 命令都是 h 开头
| 命令 | 说明 |
| ------------ | --------------- |
| hset | 设置一个key/value对 |
| hget | 获得一个key对应的value |
| hgetall | 获得所有的key/value对 |
| hdel | 删除某一个key/value对 |
| hexists | 判断一个key是否存在 |
| hkeys | 获得所有的key |
| hvals | 获得所有的value |
| hmset | 设置多个key/value |
| hmget | 获得多个key的value |
| hsetnx | 设置一个不存在的key的值 |
| hincrby | 为value进行加法运算 |
| hincrbyfloat | 为value加入浮点值 |
12.1 向 hash 中添加值:hset¶

12.2 得到 hash 中的指定 filed 的值:hget¶
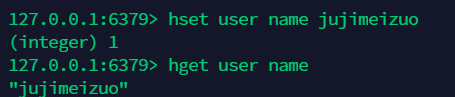
12.3 得到 hash 中的所有值 :hgetall ¶
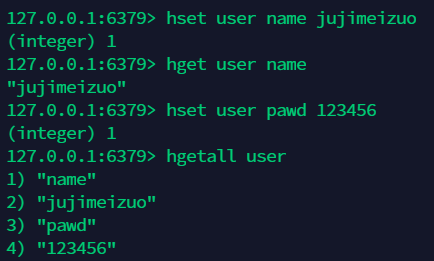
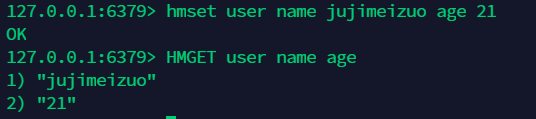
12.4 批量添加和获取:hmset hmget¶
12.5 删除指定的字段:hdel¶
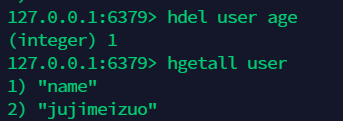
12.6 获取 hash 的字段长度:hlen¶
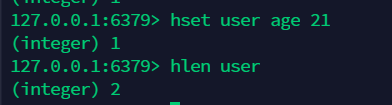
12.7 判断 hash 中的字段是否存在:hexist¶
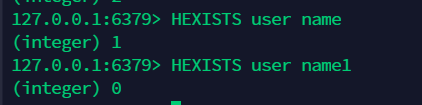
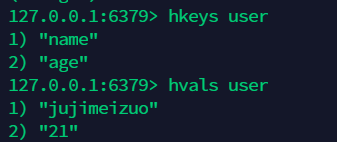
12.8 获取所有的 key( 字段 )hkeys, 获取所有的 value:hvals¶
12.9 指定增量:hincrby¶
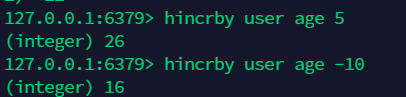
hash 变更的数据 user name age, 尤其是是用户信息之类的,经常变动的信息! hash 更适合于对象的存储,String 更加适合字符串存储!
13. Zset 详解 ¶
zset 是有序不可重复的集合 ,zset 命令都是 z 开头 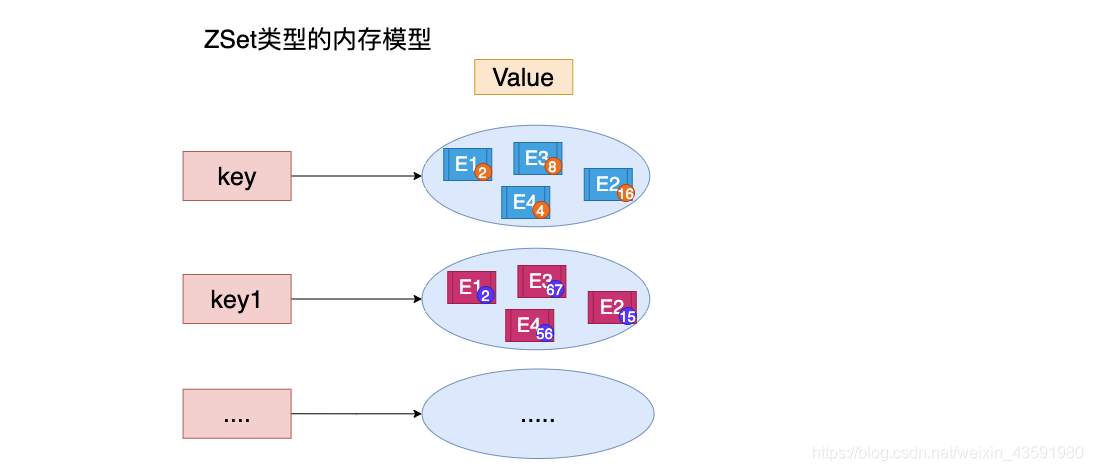
| 命令 | 说明 |
| ---------------------- | -------------- |
| zadd | 添加一个有序集合元素 |
| zcard | 返回集合的元素个数 |
| zrange 升序 zrevrange 降序 | 返回一个范围内的元素 |
| zrangebyscore | 按照分数查找一个范围内的元素 |
| zrank | 返回排名 |
| zrevrank | 倒序排名 |
| zscore | 显示某一个元素的分数 |
| zrem | 移除某一个元素 |
| zincrby | 给某个特定元素加分 |
13.1 添加数据:zadd¶
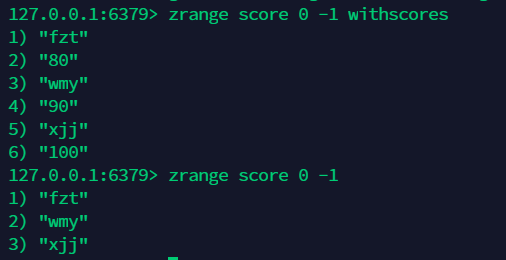
13.2 获取所有值 , 按照索引获取:zrange¶
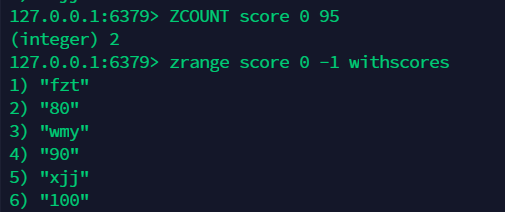
13.3 获取所有值,按照 score 获取:zrangebyscore¶
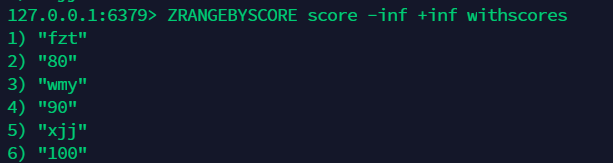
13.4 移除元素:zrem¶
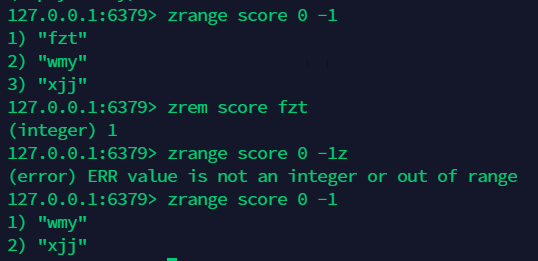
13.5 得到元素的个数 :zcard ¶

13.6 获取指定区间的成员数量:zcount¶
ZSET 官方 可排序 SET sortSet
14. geospatial¶
15. bitmaps¶
bitmap 即位存储,适用于只有两面性的内容。如:可以用 bitmap 存储用户是否登录,是否注册,是否打卡等等。bitmap 的值只有 0 和 1 两个值。
15.1 存储数据:setbit¶
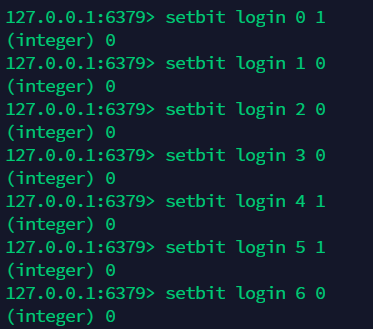
15.2 获取指定下标的值:getbit¶
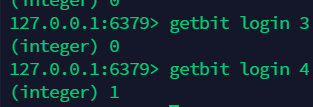
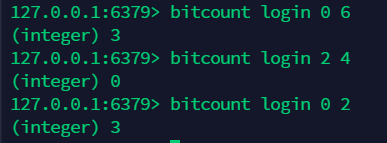
15.3 统计 bitmap 中 1 的位数:bitcount¶
16. hyperloglogs¶
用于统计基数(即不重复的数据), 可以用于统计网页访问量
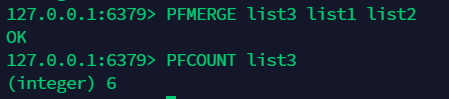
16.1 添加:pfadd¶

16.2 计数:pfcount¶
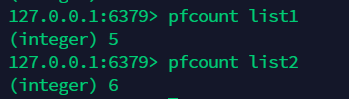
16.3 合并:pfmerge¶