CUT3R¶
约 435 个字 预计阅读时间 1 分钟
Abstract
 CUT3R: Continuous 3D Perception Model with Persistent State
CUT3R: Continuous 3D Perception Model with Persistent StateIntroduction¶
问题导向
动态物体、稀疏观察、退化的相机运动
解决方案
- 一个仅基于 RGB 输入就能处理各种 3D 任务的在线 3D 推理框架
- Dynamic Scene Reconstruction
- 3D Reconstruction(Video)
- 3D Reconstruction(Photo Collection)
- Inferring Unseen Structure
- 该方法具有一个状态的循环模型,能随着每次新的观察不断更新其状态表示,读取信息以预测视图的 3D 属性(点图、相机参数)

Method¶
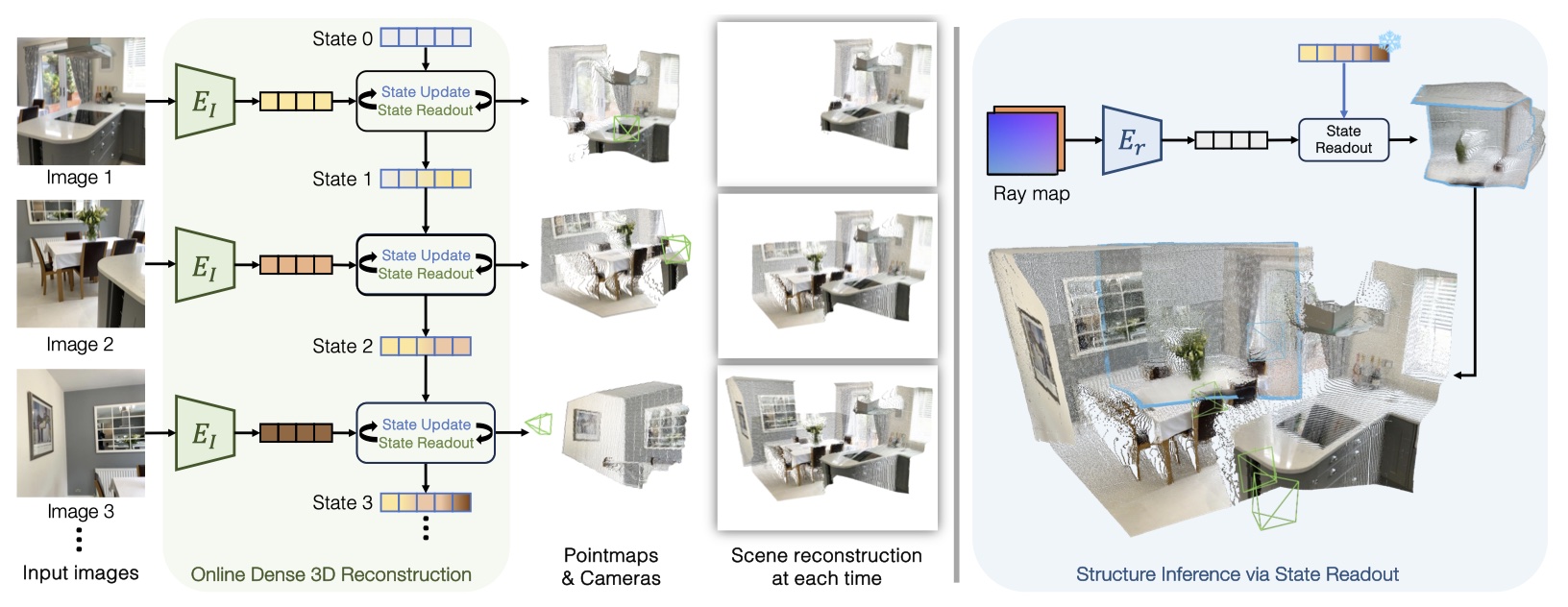
State-Input Interaction Mechanism¶
- 将图像流作为输入,对于当前图像 \(I_t\),首先用 ViT 进行编码为 token \(F_t = Encoder_i(I_t)\)(状态也表示为一组 tokens,状态初始化为所有场景共享的一组可学习的 token)
- 图像 token 与状态以两种方式交互
- 利用当前图像的信息更新状态(state-update)
- 从状态中读取上下文,融合存储的过去信息(state-readout)
-
这种交互通过两个相互连接的 Transformer decoders 实现,共同对图像和状态 token 进行操作:
\[ [\boldsymbol{z}_t^{\prime},\boldsymbol{F}_t^{\prime}],\boldsymbol{s}_t=\mathrm{Decoders}([\boldsymbol{z},\boldsymbol{F}_t],\boldsymbol{s}_{t-1}) \] -
通过交互后,可以从 \(F_t^\prime\) 和 \(z_t^\prime\) 提取 PointMap 和 ConfidenceMap,同时预测两个坐标系的相对变换
Querying the State with Unseen Views¶
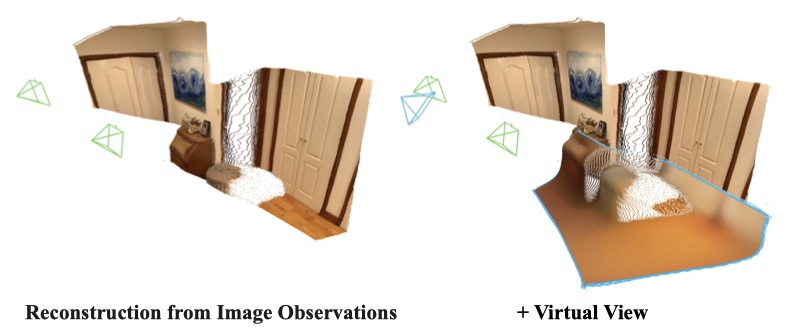
- 使用虚拟相机作为查询,从状态中提取信息。虚拟相机的内参和外参表示为一个光线映射 R,对每个像素处光线的起点和方向进行编码 \(F_r = Encoder_r(\blod{R})\),后续步骤和上面相同
- 用相同的 head 将 \(F_r^\prime\) 解析为显式表示
- 另外引入一个 head 解码颜色信息
Experiments¶
Reference¶
最后更新:
2025年5月9日 15:51:31
创建日期: 2023年8月26日 15:00:56
创建日期: 2023年8月26日 15:00:56