DUSt3R¶
约 1321 个字 35 行代码 预计阅读时间 5 分钟
Abstract
- paper:
 DUSt3R: Geometric 3D Vision Made Easy
DUSt3R: Geometric 3D Vision Made Easy - code: dust3r
Introduction¶
问题导向
传统三维重建都是基于 MVS 原理,将任务拆解为多个子问题,这样会存在每个子问题都解不好导致下一步引入噪声、子问题缺乏沟通、关键步骤可能会失败等等挑战。
解决方案
DUSt3R 解决的任务是基于图像的密集 3D 重建。利用端到端的思想,将传统 SfM 点云构建的多类子任务综合为一个统一的 ViT 神经网络模型,从 2D 图像直接估计 3D 点云。 同时利用 Croco 的预训练范式,能够在不校准相机信息以及 Pose 的情况下,重建两张图像的空间稠密点云,而针对三张图像及以上,经过全局对齐的方式,统一多图的视点并重建三维模型。
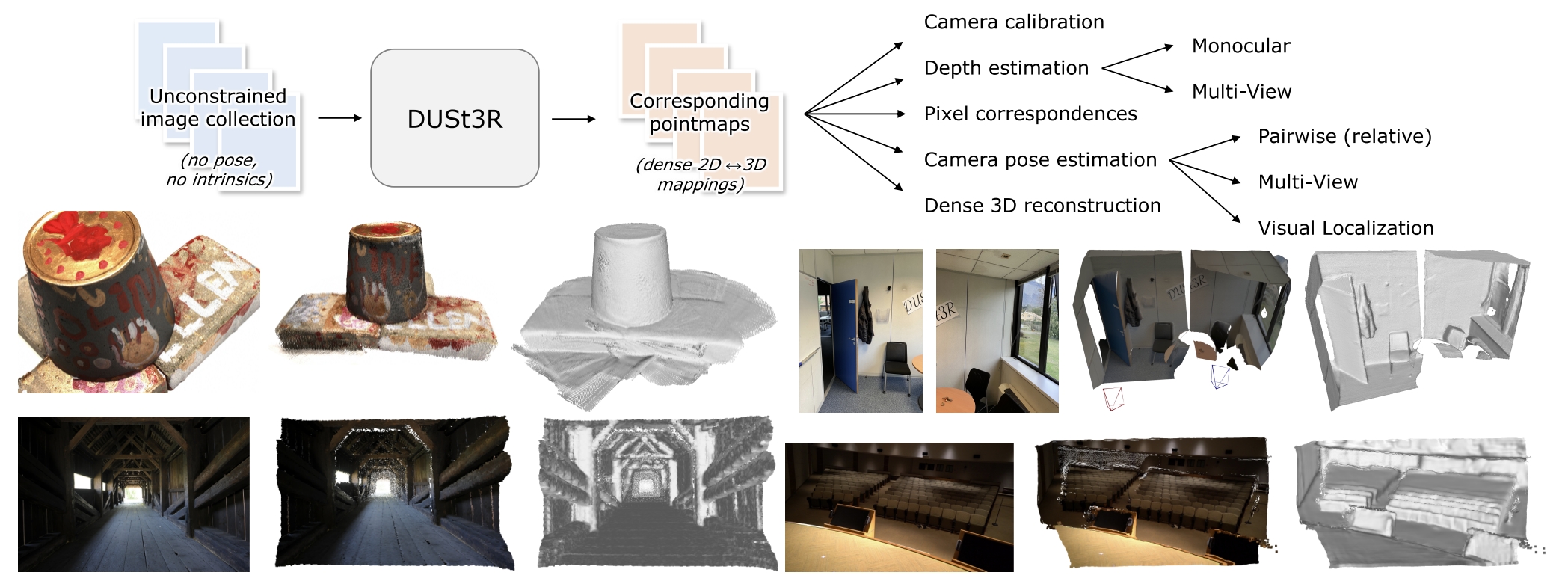
Method¶
PointMap & ConfidenceMap¶
- DUSt3R Input:一个场景的一系列 2D 图像
- DUSt3R Output:对于 H * W * 3 的 RGB 图像,输出一个 H * W * 3 的 PointMap 和 H * W 的 ConfidenceMap
- ConfidenceMap: 每个像素对应的 PointMap 的置信度
- PointMap: 每个 RGB 图像的像素点对应的三维空间坐标。
- 物理含义:从光心与对应像素的组成的射线,遇到的最近的空间结构在相机坐标系中的坐标。
- 相机参数已知时,可以通过深度图投影得到。
Model¶
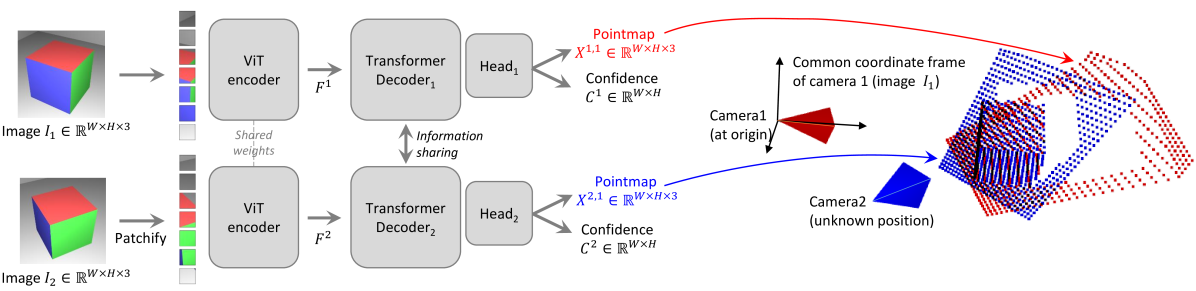
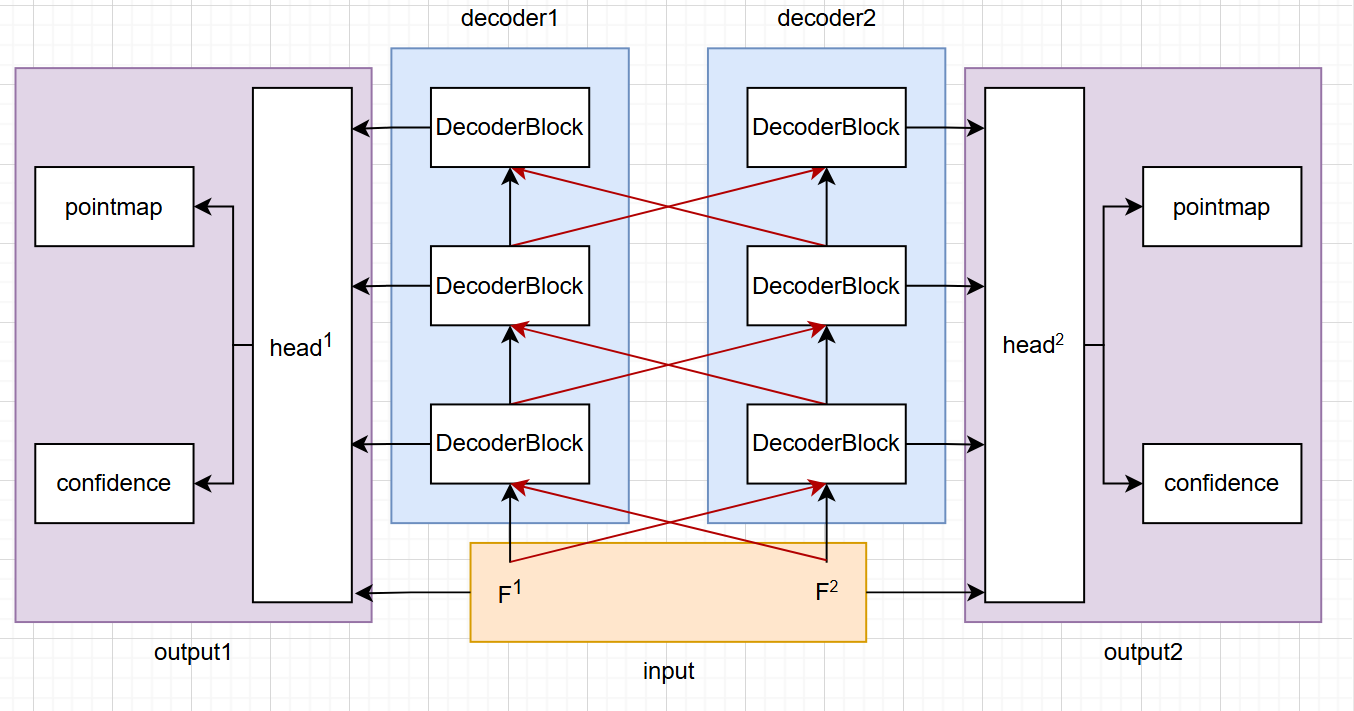
- 输入的两张图像 \(I^1\)、\(I^2\) 会用同一个 ViT 模型进行编码得到对应的 \(F^1\)、\(F^2\) 特征图,然后基于 Transformer 和 Cross-Attention 来融合两帧的信息进行解码,最后把所有解码器的输出用 DPT head 来融合并输出最终每一帧图像的 PointMap 和 ConfidenceMap
。 (代码里的 head 有 linear 和 dpt 两种,先用 linear 进行低分辨率训练,然后 dpt 在更高分辨率上训练从而节省时间) - 为了避免后续配准,直接以第一张图像作为基准标准系,网络输出的第二张图像的 PointMap 直接位于基准标准系下。
- 整个过程完全不带有任何几何约束,输出的 PointMap 是不带尺度信息,所以 PointMap 对应于每个像素的连线不一定会交于同一点(光心
) 。 -
模型输出结果:

Loss¶
- 损失含有由两部分组成,第一部分是预测点云和真值点云在欧式空间的距离,第二部分是置信度得分。
-
第一部分:
- 假设第 j 张图像(j=1,2)的第 i 个像素在基准坐标系对应的真实空间点为 \(\bar{X}_i^j\),而预测为 \(X_i^j\),那么损失函数为:
\[ \mathcal{l}_{regr}(j, i) = \left\| \frac{1}{z}\bar{X}_i^j - \frac{1}{z} X_i^j \right\| \]- 其中 \(\frac{1}{z}\) 是归一化因子,通过计算所有有效点到原点的平均距离来确定
- 第二部分:
- 网络还会输出一个 ConfidenceMap,将其融合进 loss,将置信度和对应的 3D 点距离损失相乘,这样 3D 点预测比较好的像素点对应的置信度能保留,反之则会降低置信度。
\[
\mathcal{L}_{conf} = \sum_{v \in \{1,2\}} \sum_{i \in D^v} C_i^v \mathcal{l}_{regr}(v, i) - \alpha \log C_i^v
\]
全局对齐 ¶
-
上述 pipeline 一次只能输入两张图,但是实际肯定不止这么点,作者是这样处理的:
- 为有重叠区域的图像两两构建匹配对,检测重叠区域用特征点法也好,用 encoder 输出的隐式特征也好,总之就是把能看到同一区域的图像两两相连起来。
- 把上述每对 pair 送到 pipeline 里去检测,用平均置信度来踢掉不太行的 pair。
- 这样就得到了一堆点云,对于每对图像,预测出成对的点云和置信度图
- 但是这些点云都不在同一个基准标准系里,然后每个点云的尺度还不一定一样,所以需要一个优化来弄到一个共同坐标系里。这个优化就是为每对图像引入一个成对姿态 \(P_e\) 和一个缩放因子 \(\sigma_e > 0\),然后构建一个优化来同时优化 \(P_e\)、\(\sigma_e\) 和 全局点云 \(X\),为了避免所有缩放因子 \(\sigma_e\) 都趋于 0 的平凡最优解,添加约束条件 \(\prod_e \sigma_e = 1\):
\[ X^* = \argmin_{X, P, \sigma} \sum_{e \in E} \sum_{v \in e} \sum_{i=1}^{HW} C_{v,e,i} \left \| X_{v, i} - \sigma_e P_e X_{v,e,i} \right \| \] -
作者表明,相比于传统的 BA 利用重投影,在 2D 图像上进行误差优化,本文的全局对齐是在 3D 空间中进行优化的,采用了标准的梯度下降法,能够快速地收敛。
- 得到世界坐标系下的点云后,进一步通过各种公式得到:相机位姿、内参、深度图等信息。
Experiments¶
- bash
- py
from dust3r.inference import inference
from dust3r.model import AsymmetricCroCo3DStereo
from dust3r.utils.image import load_images
from dust3r.image_pairs import make_pairs
from dust3r.cloud_opt import global_aligner, GlobalAlignerMode
if __name__ == '__main__':
device = 'cuda'
batch_size = 1
schedule = 'cosine'
lr = 0.01
niter = 300
# 模型读取
model_name = "naver/DUSt3R_ViTLarge_BaseDecoder_512_dpt"
model = AsymmetricCroCo3DStereo.from_pretrained(model_name).to(device)
# 图像列表
images = load_images(['1.jpg',
'2.jpg',
'3.jpg',
'4.jpg',
'5.jpg',
'6.jpg',
'7.jpg',
'8.jpg',
], size=512)
# 文件处理
pairs = make_pairs(images, scene_graph='complete', symmetrize=True)
# 三维重建
output = inference(pairs, model, device, batch_size=batch_size)
# 全局优化
scene = global_aligner(output, device=device, mode=GlobalAlignerMode.PointCloudOptimizer)
loss = scene.compute_global_alignment(init="mst", niter=niter, schedule=schedule, lr=lr)
# 上才艺
scene.show()
| two images | mutli images |
|---|---|
 |
 |
Reference¶
- 【论文解读】CVPR2024:DUSt3R: Geometric 3D Vision Made Easy
- DUSt3R 论文与代码解读
- 解读:DUSt3R: Geometric 3D Vision Made Easy
- 计算机视觉 2—理解 DUSt3R 三维重建新思路
- Dust3r 文章 + 代码串读(无敌详细 / 引经据典 / 疯狂解读)
- https://zhuanlan.zhihu.com/p/28169401009
- 论文阅读笔记之《MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors》
最后更新:
2025年5月9日 15:51:31
创建日期: 2023年8月26日 15:00:56
创建日期: 2023年8月26日 15:00:56