Easi3R¶
约 622 个字 预计阅读时间 2 分钟
Abstract
 Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
Easi3R: Estimating Disentangled Motion from DUSt3R Without TrainingIntroduction¶
问题导向
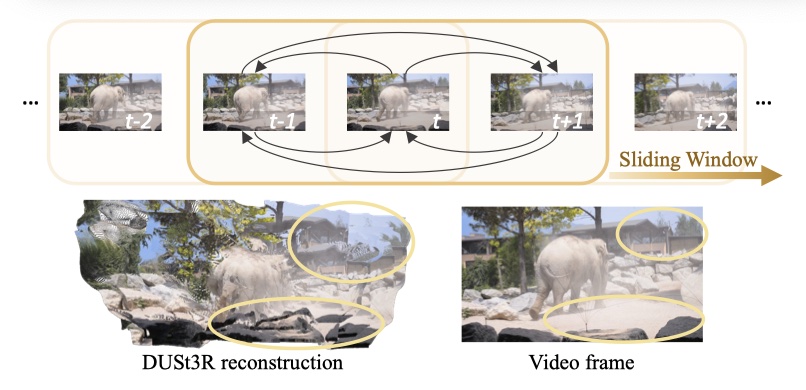
- DUSt3R 无法适用于静态场景。
- MonST3R 用动态场景的数据集重新训练,但是数据有限,很难保证训练模型的泛化能力,且增大复杂度。
解决方案
通过对推理阶段的 attention 的调整来实现将 DUSt3R 直接用到 dynamic 场景,避免预训练或 fine-tune。
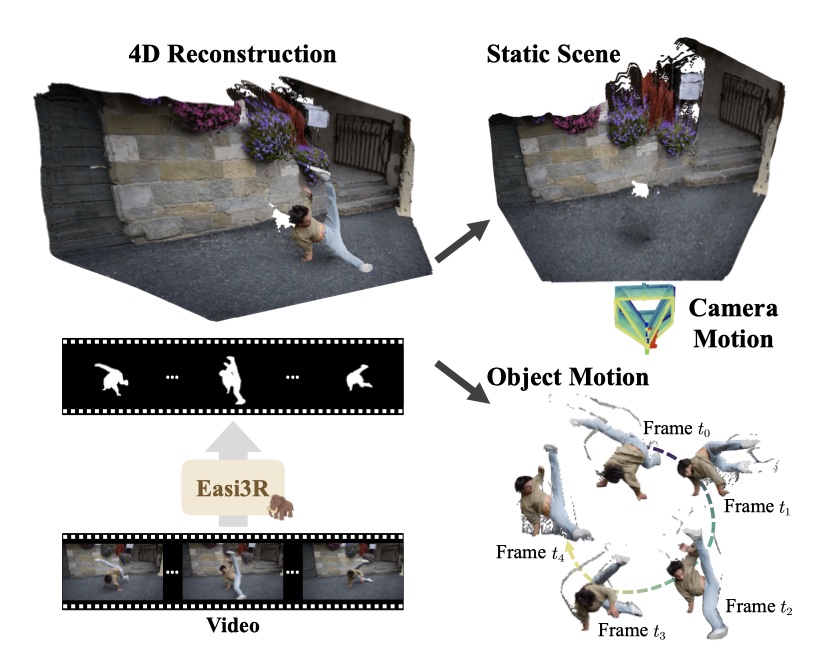
Method¶
Network Architecture¶
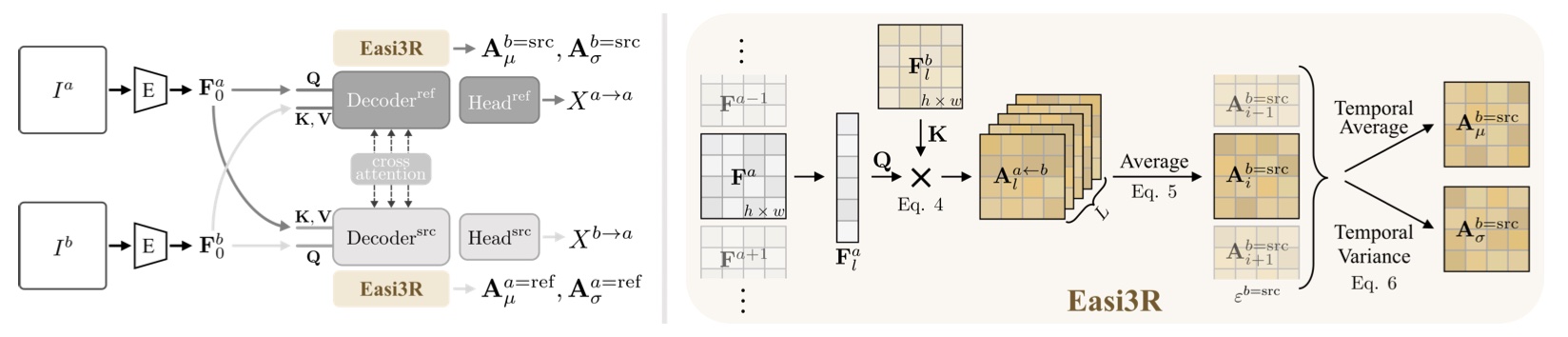
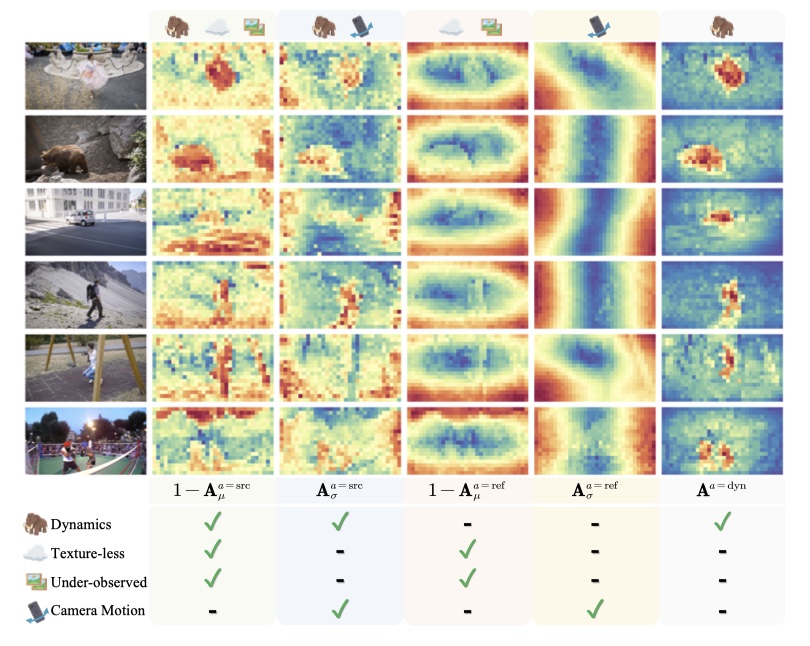
- Insight: DUSt3R 隐式学习刚性视图变换,违反极几何约束(无纹理、观测不足、动态区域)的 attention 值都比较小,通过在空间和时间维度上 aggregate cross-attention 的输出,很简单地将 attention 值较小的区域分割开来实现动态物体分割。
- Spaital attention maps
- 图像特征 \(F\) 可以通过可训练的线性函数投影到各自分支的 \(Q、K\),然后计算 corss-attention map 得到 \(\mathbf{A}_{l}^{a\leftarrow b}=\mathbf{Q}_{l}^{a}\mathbf{K}_{l}^{b^{T}}/\sqrt{c},\quad\mathbf{A}_{l}^{b\leftarrow a}=\mathbf{Q}_{l}^{b}\mathbf{K}_{l}^{aT}/\sqrt{c}\)。紧接着 \(\mathbf{A}_{l}^{a\leftarrow b}\) 可以 warp \(V\),\(\mathbf{A}_{l}^{a\leftarrow b}\) 决定在第 l 个解码器中的信息如何从 b aggregate to a。
- 每个 token 的空间贡献不同,所以对 attention maps 进行加权平均。
-
Temporal attention maps:
- 将单对图像扩展到多对图像,需要考虑时间 attention 相关性,将上一步的 A 计算均值和方差。
-
最终的时间交叉注意力图:
dynamic Object Segmentation¶
使用下面公式得到每帧动态目标分割 \(\mathbf{M}^t=\begin{bmatrix}\mathbf{A}^{t=\mathrm{dyn}}>\alpha\end{bmatrix}\)(分割是逐帧的,为了增强时间一致性,作者应用了一种特征聚类方法,融合所有帧的信息
\[
\mathbf{A}^{a=\mathrm{dyn}}=(1-\mathbf{A}_{\mu}^{a=\mathrm{src}})\cdot\mathbf{A}_{\sigma}^{a=\mathrm{src}}\cdot\mathbf{A}_{\mu}^{a=\mathrm{ref}}\cdot(1-\mathbf{A}_{\sigma}^{a=\mathrm{ref}})
\]

4D Reconstruction¶
- 经过动态物体分割后,如果用黑色像素替换动态区域,这种方法会显著降低重建性能,原因是黑色像素和 mask token 会导致分布外的输入,解决方案是在 attention layers 中应用 mask。
- Attention re-weighting:通过削弱与动态区域相关的 attetnion value 来修改 corss-attention map,对网络进行二次推理,对分配的动态区域的 attention map 进行 mask,使其 attention value = 0,其余区域不变。
- 同时将光流也结合进动态区域分割。
Experiments¶
Reference¶
最后更新:
2025年5月10日 15:41:56
创建日期: 2023年8月26日 15:00:56
创建日期: 2023年8月26日 15:00:56