Fast3R¶
约 308 个字 预计阅读时间 1 分钟
Abstract
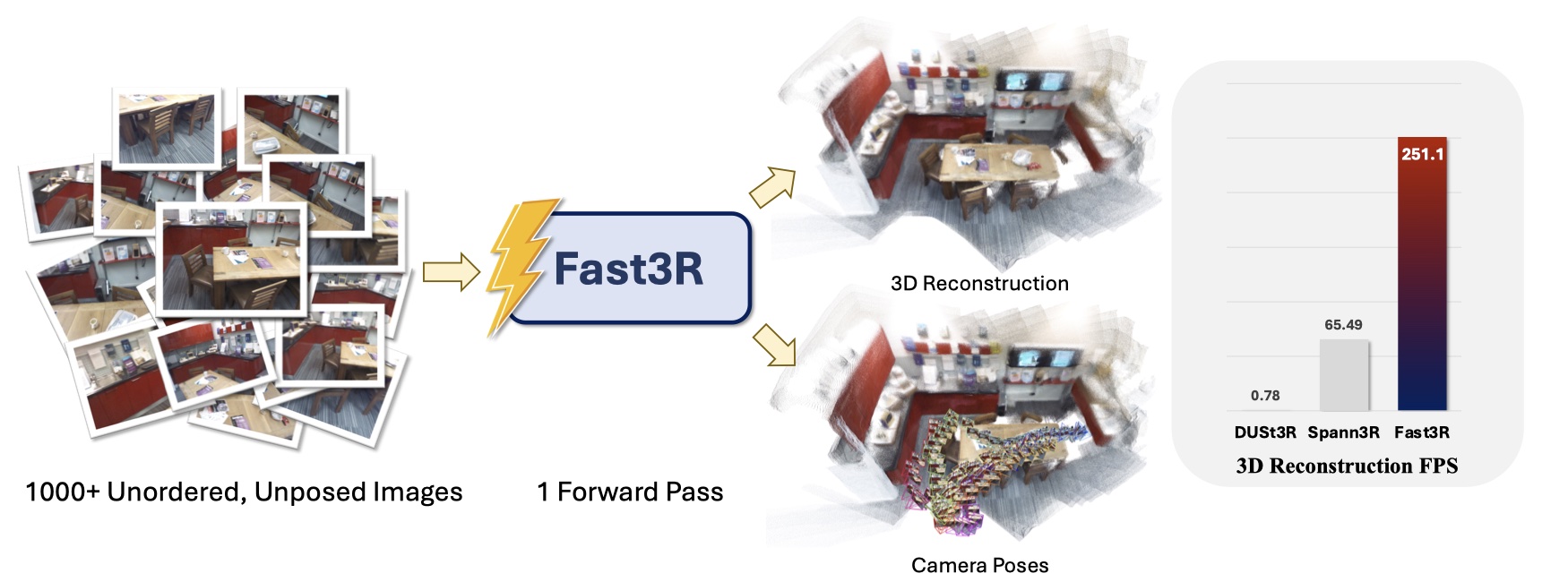
 Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward PassIntroduction¶
问题导向
DUSt3R 的效率问题。
解决方案
类似于 Spann3R,并行处理多个视角。在一次前向传播中处理 N 张图像,避免迭代对齐的需求。 DUSt3R 0.78 FPS, Spann3R 75.49 FPS, Fast3R 250 FPS。
Method¶
Network Architecture¶
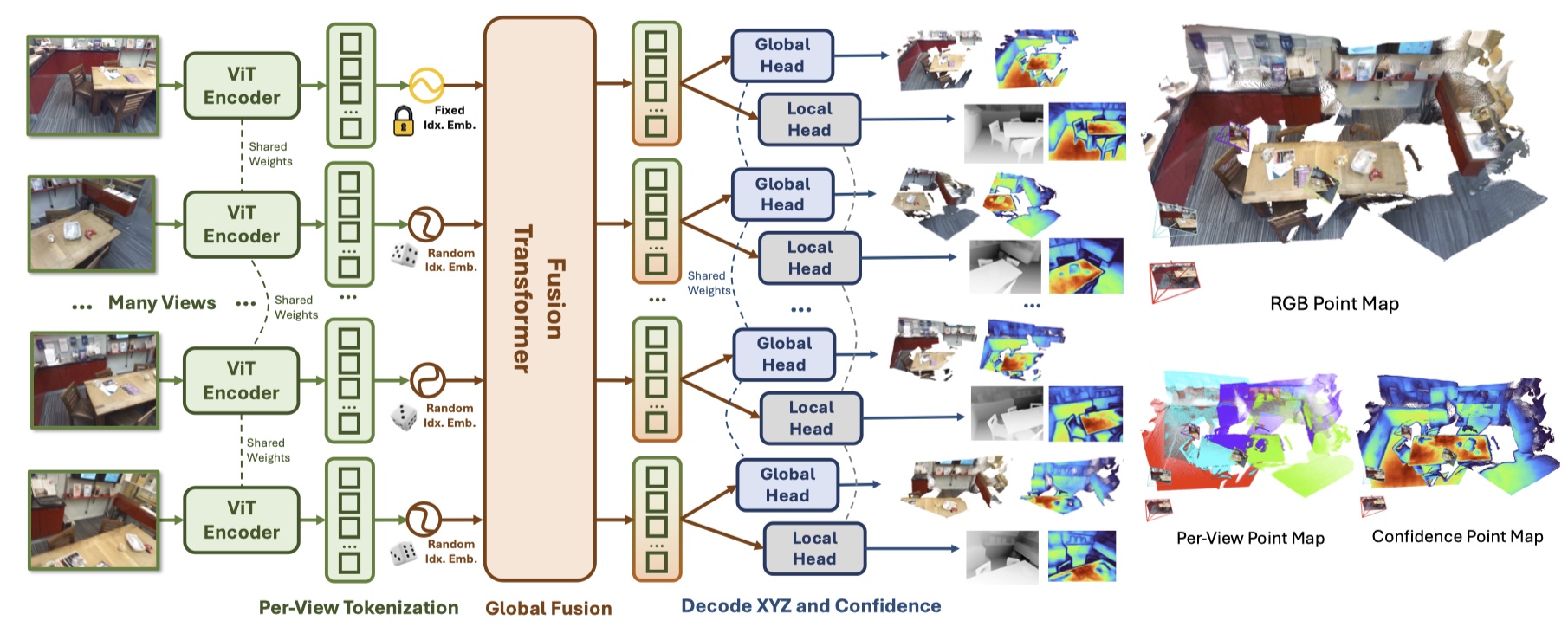
- Image Encoder:和 DUSt3R 一样采用 CroCo ViT(作者说 DINOv2 类似也可以)在将图像块特征传递给 Fusion Transformer 前,添加一个一维的 image index positional embeddings。
- Fusion Transformer:计算量最大的部分。采用类似 ViT-L 的 24 层的 Transformer,接收来自所有视图的 concatenated encoded image patches,并执行 all-to-all self-attention。
- Pointmap Decoding Heads:使用两个独立的 DPT decoding head 将所有的 tokens 映射到各自的 local pointmaps 和 global pointmaps,以及 confidence pointmaps。
Loss¶
\[
\mathcal{L}_\mathrm{total}=\mathcal{L}_\mathrm{X_G}+\mathcal{L}_\mathrm{X_L} \\
\mathcal{L}_{\mathbf{X}}(\hat{\Sigma},\hat{\mathbf{X}},\mathbf{X})=\frac{1}{|\mathbf{X}|}\sum\hat{\Sigma}_+\cdot\ell_{\mathrm{regr}}(\hat{\mathbf{X}},\mathbf{X})+\alpha\log(\hat{\Sigma}_+) \\
\ell_{\mathrm{regr}}(\hat{\mathbf{X}},\mathbf{X})=\left\|\frac{1}{\hat{z}}\hat{\mathbf{X}}-\frac{1}{z}\mathbf{X}\right\|_{2},\quad z=\frac{1}{|\mathbf{X}|}\sum_{x\in\mathbf{X}}\lVert x\rVert_{2}
\]
和 DUSt3R 差不多。
Experiments¶
Reference¶
最后更新:
2025年5月9日 15:51:31
创建日期: 2023年8月26日 15:00:56
创建日期: 2023年8月26日 15:00:56