MonST3R¶
约 416 个字 预计阅读时间 1 分钟
Abstract
 MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
MonST3R: A Simple Approach for Estimating Geometry in the Presence of MotionIntroduction¶
问题导向
DUSt3R 在动态场景中的局限性:
- DUSt3R 对齐了移动的前景物体,但由于只在静态场景中进行训练,导致静态背景元素的对齐出现不正确的对齐。
- DUSt3R 无法估计前景物体的几何形状和深度,并将它们放在背景中。

解决方案
MonST3R 直接从动态场景中估计每个 timestep 下的的 pointmap。然而缺乏适合的训练数据(带深度标签的动态视频

Method¶
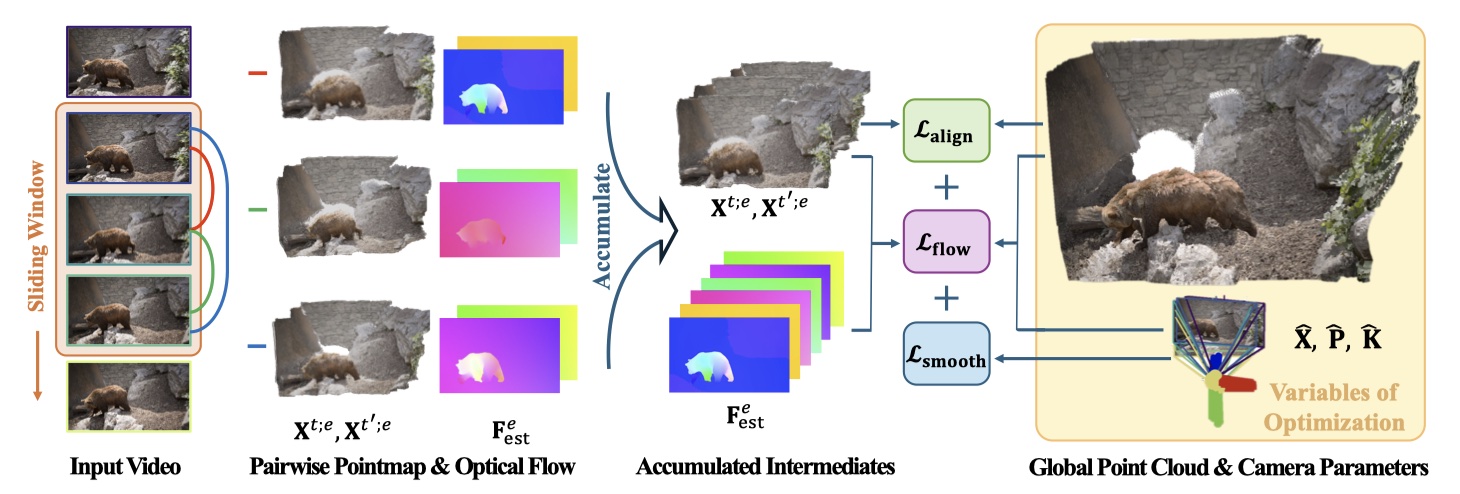
- 对于 finetune 过程,只微调了 prediction head 以及 decoder,而 encoder 固定不变。
- 额外增加了 RAFT 和 SAM2 用来分离动态和静态。
- 对于 多个视角下的全局优化仍然采用 DUSt3R 的全局 alignment 的模块,但是分别构建了三个 loss(光流、相机位姿的平衡、全局对齐)进而实现动态场景下的全局 pointmap 的构建。
Experiments¶
Reference¶
- 论文学习及实验笔记之——《MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion》
- 【动态三维重建】MonST3R:运动中的几何估计
- MonST3R | UC 伯克利、DeepMind 等提出的运动状态下估算几何图形的先进方法
最后更新:
2025年5月9日 15:51:31
创建日期: 2023年8月26日 15:00:56
创建日期: 2023年8月26日 15:00:56