PAGE-4D¶
约 1301 个字 预计阅读时间 4 分钟
Abstract
 PAGE-4D: Disentangled Pose and Geometry Estimation for 4D Perception
PAGE-4D: Disentangled Pose and Geometry Estimation for 4D PerceptionIntroduction¶
问题导向
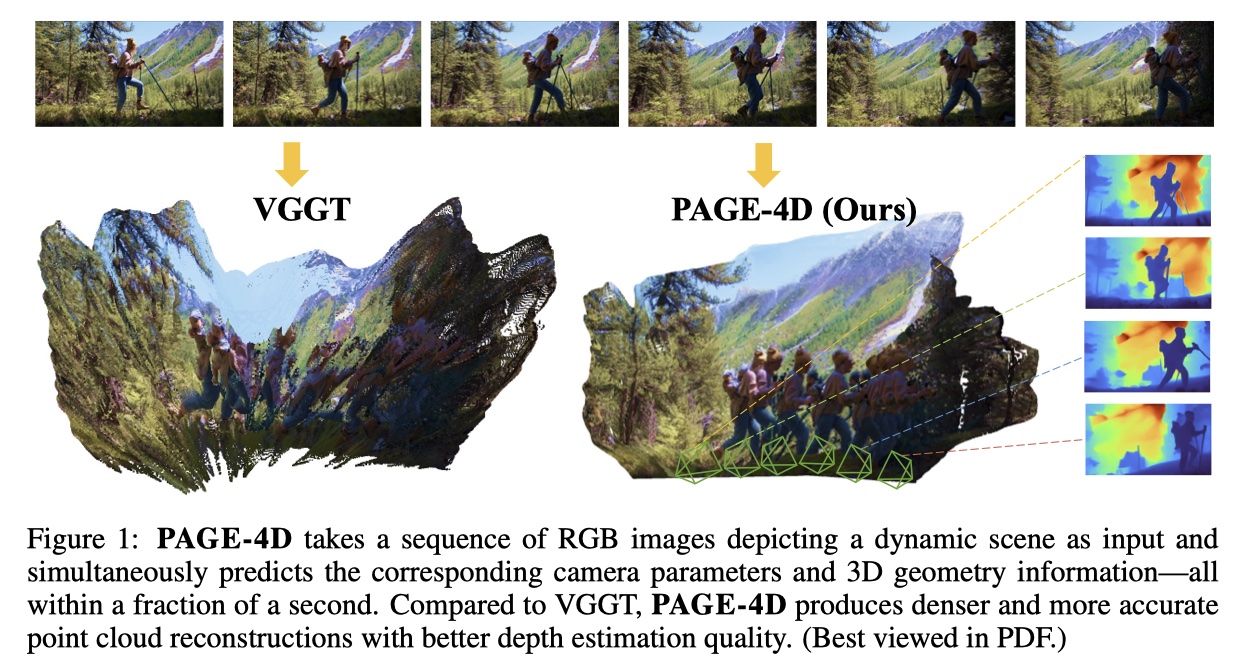
VGGT 在处理涉及运动和变形的复杂动态场景时性能显著下降。 多任务 4D 重建中的一个核心挑战是任务之间的固有冲突:精确的相机位姿估计需要抑制动态区域,而几何重建则需要对这些区域进行建模;
解决方案
- PAGE-4D 是一种前馈模型,将 VGGT 扩展到动态场景,实现相机位姿估计、深度预测和点云重建,而无需后处理; 提出一种动态感知聚合器,通过预测动态感知掩码来分离静态和动态信息——在位姿估计时抑制运动线索,而在几何重建中增强这些线索;
Method¶
VGGT's limitations in dynamic scenes¶
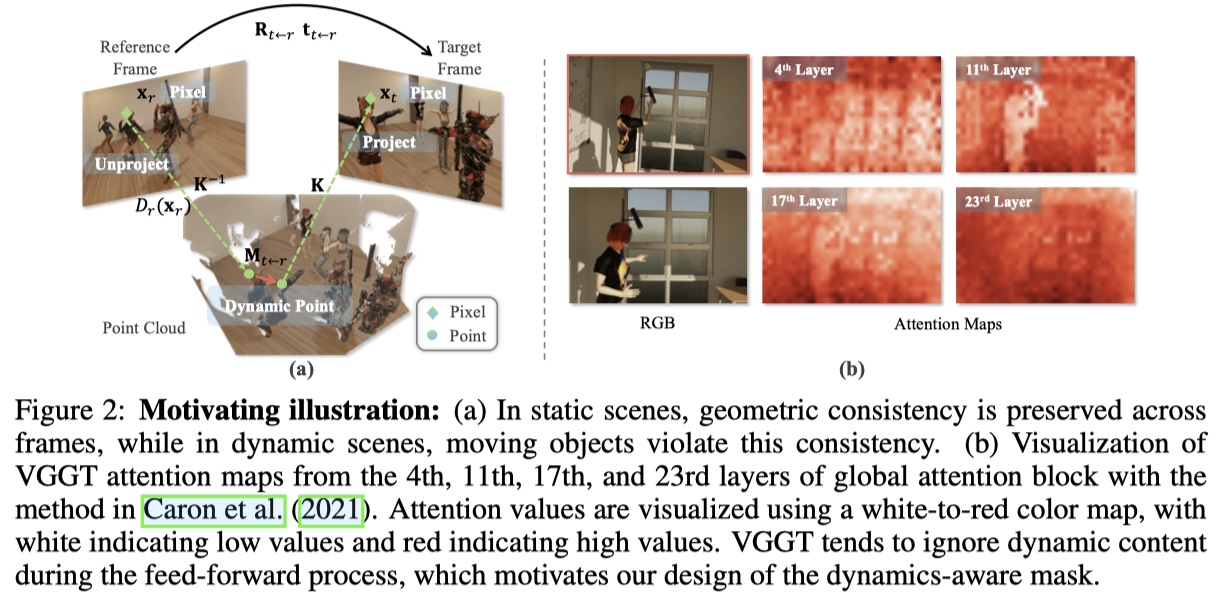
- 通过观察 VGGT 的关键层,发现与静态区域相比,动态区域的激活较弱,这表明 VGGT 倾向于忽略动态内容;
- 通过抑制动态标记的注意力,虽然改进了相机位子估计,但同时也导致几何性能急剧下降,这表明 VGGT 在动态场景中的一个基本矛盾:虽然抑制动态区域有助于相机位子顾及以保持对极一致性,但几何性能却需要利用这些动态区域的运动线索;
- 从公式原理的角度出发(具体描述看原文
) :- 动态环境下,用于几何估计的公式对于目标帧和参考帧之间所有未遮挡的像素对有效,而用于位姿估计的公式仅适用于未遮挡像素的静态子集;
- 动态环境下,相机位姿估计易受到动态运动的影响,但可以从该运动中获取线索。
PAGE-4D¶
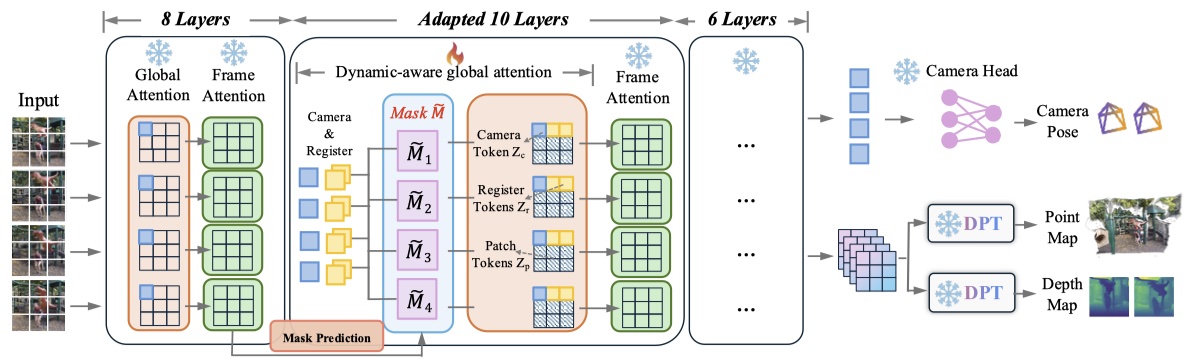
PAGE-4D 组成
- 一个预训练的 DINO encoder,用于提取图像级表征(from VGGT
) ; - 一个 dynamics-aware aggregator,通过三个模块整合空间和时间线索——用于帧间 patch 关系的 Frame Attention、用于帧内 patch 关系的 Global Attention 以及用于分离动态与静态内容的 Dynamics-Aware Global Attention;
- 用于深度、3D 点图的轻量级 Decoder(from VGGT
) ; - 用于相机位姿估计的 Decoder(from VGGT
) ;
(2) 扩展为下图的三阶段动态感知聚合器:
- 第一段包含 8 层(每层一个 Global Attention Block 和一个 Frame Attention Block
) ,输出送入动态掩码预测模块,会生成一个 Mask; - 该 Mask 被用于第二段中用于分离动态和静态内容,以进行位姿和几何估计,第二段包含 10 层(每层一个 Dynamics-Aware Global Attention Block 和一个 Frame Attention Block
) ; 第三段和第一段相同,包含 6 层。
Dynamic Mask Prediction¶
- 如何选择性地抑制动态物体的影响,同时仍保留它们的几何信息,设计一个动态掩码预测模块,以自监督的方式学习哪些空间区域可能对应于动态物体;
- 给定来自聚合器的 token feature \(\mathbf{z} \in \mathbb{R}^{B \times S \times P \times d}\),首先只提取 patch tokens \(\mathbf{z}_p \in \mathbb{R}^{B \times S \times (H \cdot W) \times d}\);这些 tokens 通过线性映射被投影到低维表示中,随后通过一个深度卷积头生成掩码对数 \(\mathbf{m} = \text{ConvDepthwise}(\phi(\mathbf{z}_p)) \in \mathbb{R}^{(B \cdot S) \times 1 \times H \times W}\),为了将对数转换为抑制概率,引入可学习参数 \(\tau\) 温度 和 \(\alpha\) 缩放因子,随网络一起优化:\(\tau = \text{softplus}(\tau_{\text{logit}}) + \epsilon\),\(\alpha = \text{softplus}(\alpha_{\text{logit}}) + \epsilon\),最后的动态掩码是:
\[
\widetilde{\mathbf{M}}=-\alpha \cdot \sigma\left(-\frac{\mathbf{m}}{\tau}\right) \in \mathbb{R}^{B \times S \times(H \cdot W)}
\]
- 较大正对数的区域对应着有剧烈动态运动的 patches,因此会被抑制。这种设计能使网络学习自适应、连续的抑制权重,而非二进制掩码,对处理模糊的运动边界和部分遮挡时更鲁棒。
Mask Attention¶
- 得到 \(\widetilde{\mathbf{M}}\) 后,可以直接融入 Transformer 的注意力机制中,给定 Q K V,注意力计算为
\[
\operatorname{Attn}(\mathbf{Q}, \mathbf{K}, \mathbf{V})=\operatorname{softmax}\left(\frac{\mathbf{Q} \mathbf{K}^{\top}}{\sqrt{d}}+\widetilde{\mathbf{M}}\right) \mathbf{V}
\]
- 此外,该掩码可用于位姿估计(确保位姿估计与极线几何和静态场景约束保持一致
) ,不用于深度和点图(网络可利用动态运动线索来提高点图重建和 2D-3D 跟踪精度) 。
Training Details¶
- Fine-tuning Strategy:
- 只更新中间 10 层(仅模型的 30%
) ,同时冻结其余的聚合器层和解码器层; - 研究表明,较低层捕获局部结构,中间层建模区域关系,较高层编码全局语义;
- 消融实验表明,较靠后的中间层对准确的几何估计贡献最为显著;
- 只更新中间 10 层(仅模型的 30%
- Loss Functions:结合对相机位姿(Huber 损失
) 、深度(带有梯度正则化的不确定性加权深度) 、点图,不包含点跟踪(不适用于动态场景) ;
\[
\mathcal{L} = \lambda_c \mathcal{L}_{camera} + \mathcal{L}_{depth} + \mathcal{L}_{pmap}
\]
Experiments¶
Reference¶
- PAGE-4D: Disentangled Pose and Geometry Estimation for 4D Perception
- [ 论文评述 ] PAGE-4D: Disentangled Pose and Geometry Estimation for 4D Perception
最后更新:
2025年11月21日 22:32:24
创建日期: 2025年11月21日 22:32:24
创建日期: 2025年11月21日 22:32:24