SLAM3R¶
约 574 个字 预计阅读时间 2 分钟
Abstract
 SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB VideosIntroduction¶
问题导向
之前的工作都是离线处理。
解决方案
SLAM3R 是一个仅使用 RGB 视频作为输入的实时稠密三维重建系统。SLAM3R 执行隐式相机定位,并更专注稠密场景映射。该系统通过前馈神经网络无缝集成局部三维重建(图像到点 I2P)和全局坐标配准(局部到全局网络 L2W
Method¶
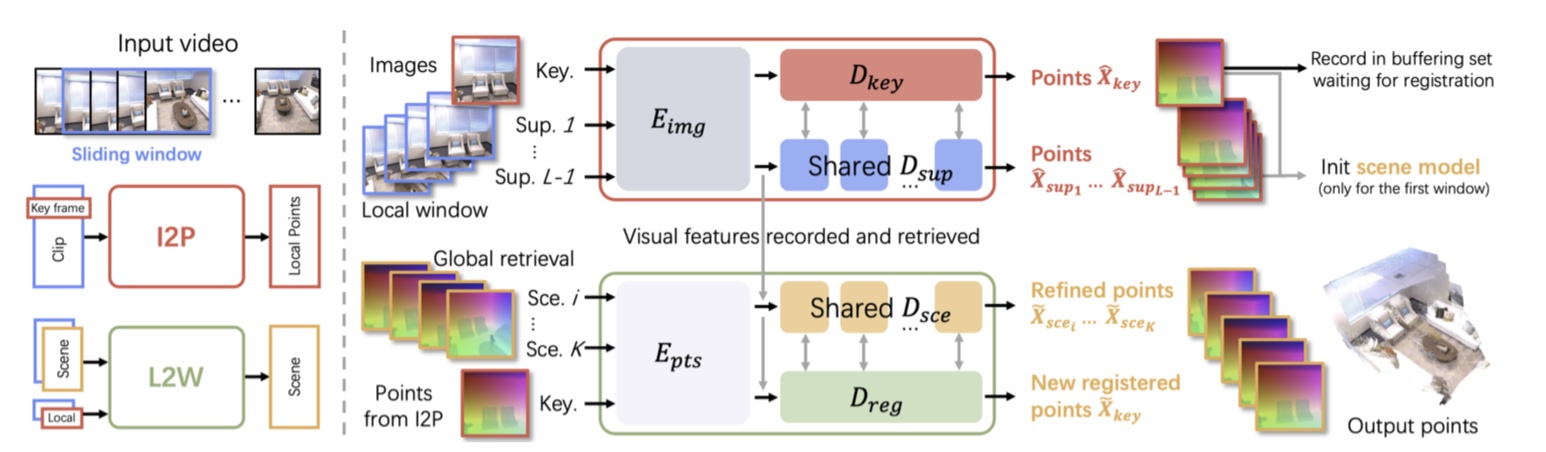
I2P Network¶
- 通过滑动窗口来处理来自输入视频流的短片段,然后提取局部的 3D 几何信息;
- 在每个窗口内,选择一帧作为关键帧(中间图像,因为最大程度地重叠)来建立参考系,其余帧用于辅助重建,全局的初始坐标使用第一个窗口;
- 采用 multi-branch ViT,适用多视角的输入,不局限于传统 SLAM 的双视角输入;
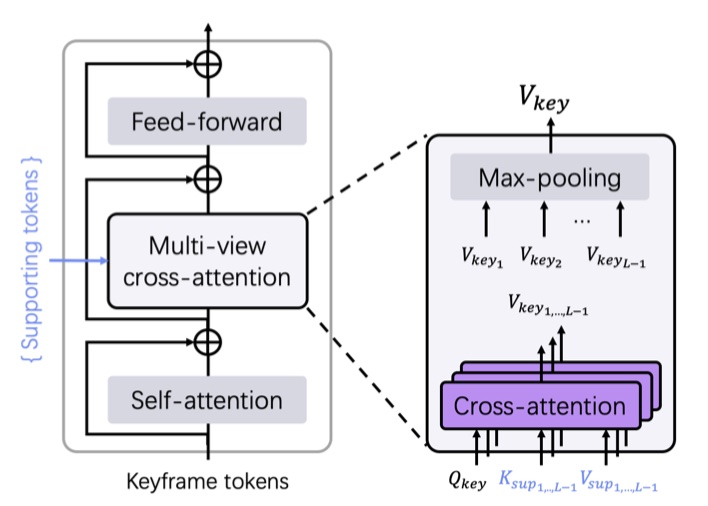
- decoder 部分,DUSt3R 使用标准的 cross attention,而 I2P 使用 multi-view cross attention(将多个视角下得到的 token 都进行 cross attention,使用最大池化聚合特征,网络结构不变,只是引入更多的数据流一起运算
) ; - 训练和 DUSt3R 一样,用 GT scene point 与估算的 pointmap 求 loss
L2W Network¶
- 与 I2P 网络类似,不同之处在于 L2W 利用多个已配准的关键帧(统称为场景帧)作为全局参考,通过采样机制保存在一个 buffer 中;
- 采用一种蓄水池策略,在 buffer 中最多保留 B 个已配准帧,当从 I2P 推断出一个新的关键帧并进行融合时,从 buffer 中检索出相关性最高的前 K 个场景帧;
- 场景初始化:第一个窗口用于初始化场景模型,执行 I2P network L 次,尝试遍历并将窗口内的每一帧指定为关键帧,然后选择总置信度得分最高的结果进行场景模型初始化;
Experiments¶
Reference¶
- SLAM3R:北大陈宝权团队等只用单目长视频就能实时重建高质量的三维稠密点云
- 论文学习及实验笔记之——《SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos》
最后更新:
2025年5月28日 10:14:32
创建日期: 2025年5月28日 10:14:32
创建日期: 2025年5月28日 10:14:32