Spann3R¶
约 735 个字 预计阅读时间 2 分钟
Abstract
- paper:
 Spann3R: 3D Reconstruction with Spatial Memory
Spann3R: 3D Reconstruction with Spatial Memory - code: spann3r
Introduction¶
问题导向
DUSt3R 只适用于稀疏数据,对于大量数据重建效率极低。毕竟是每次处理必须是一对图像。
解决方案
Spann3R 管理一个外部空间记忆,该记忆学习跟踪所有先前相关的 3D 信息,并查询 这个空间记忆来预测下一帧的 3D 结构。并且与 DUSt3R 不同的是,Spann3R 能够预测在全局坐标系中表达的每幅图像的点云图,从而消除基于优化的全局对齐的需求。50 FPS!

Method¶
Network Architecture¶
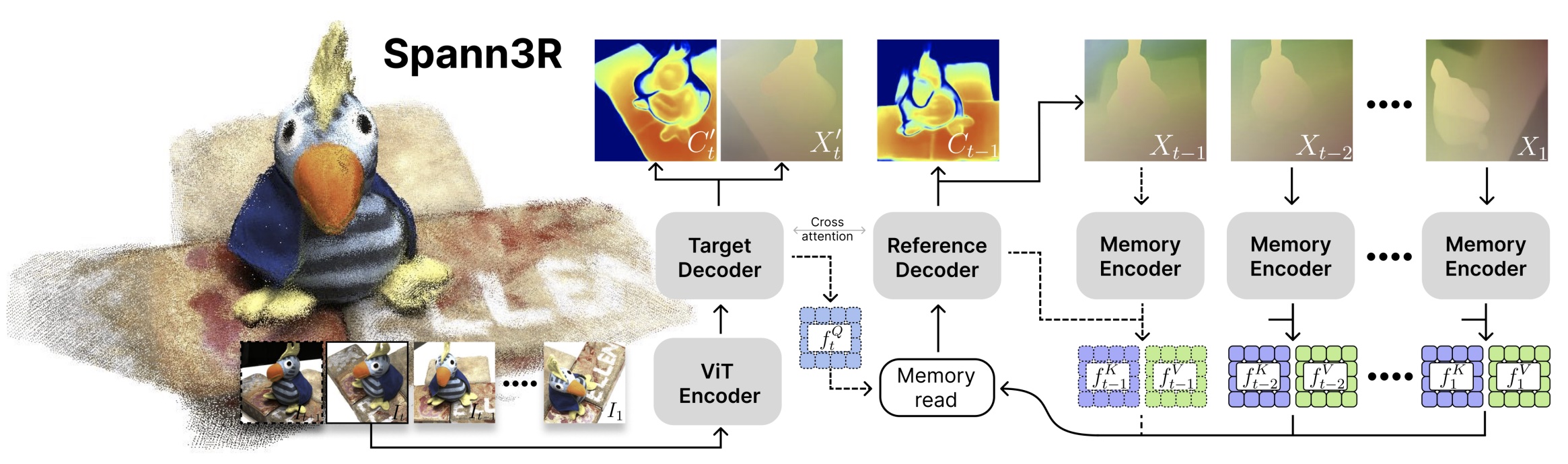
- 相比于 DUSt3R,Spann3R 多了一个内存编码器和两个 MLP head。
- Feature encoding:每次前向传播中,将当前帧 \(I_t\) 和上一个查询 \(f_{t-1}^Q\) 作为输入,用 ViT 将其编码为视觉特征 \(f_t^I\)。其中 \(f_{t-1}^Q\) 用于记忆中检索特征,以输出融合特征 \(f_{t-1}^G\)。
- Feature decoding
- 融合特征 \(f_{t-1}^G\) 和视觉特征 \(f_t^I\) 输入到交叉注意力中,推断两个特征的几何关系 \(f_t^{H^\prime}, f_{t-1}^H\)。
- \(f_{t}^{H^\prime}\) 和 \(f_t^I\) 输入到 MLP head 中生成下一步的查询特征 \(f_t^Q\)。
- 最后将 \(f_{t-1}^H\) 输入进 MLP head 生成点图 \(X_{t-1}\) 和置信度 \(C_{t-1}\)
。 (为了监督,也从 \(f_{t-1}^{H^\prime}\) 生成 一个点图和置信度。 )
- Memory encoding:将几何特征 \(f_{t-1}^H\)、视觉特征 \(f_{t-1}^I\) 和预测点图 \(X_{t-1}\) 进行编码得到内存键值特征 \(f_{t-1}^K, f_{t-1}^V\)。由于内存键值特征同时包含几何特征和视觉特征的信息,所以能基于外观和距离进行内存读取。
Spatial Memory¶
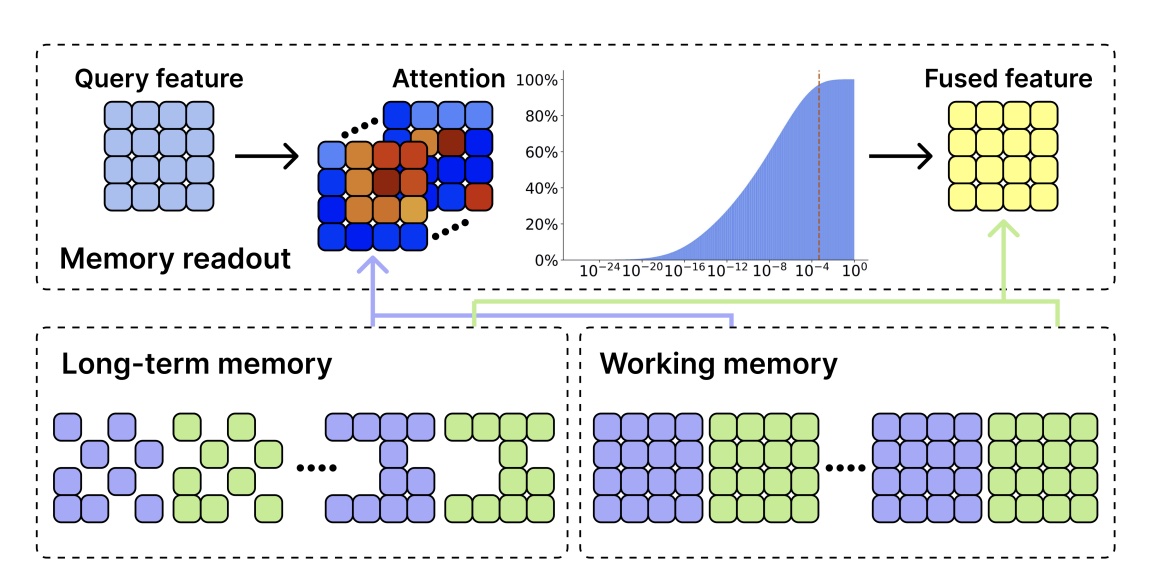
- 由一个密集的 working memory 、一个稀疏的 long-term memory 以及从 memory 中提取特征的记忆查询机制组成
- Memory query:Spatial Memory 存储所有的 key \(f^K\) 和 value \(f^V\)。为了计算融合特征 \(f_{t-1}^G\),使用 \(f_{t-1}^Q\) 应用于交叉注意力,\(f_{t-1}^G = A_{t-1}f^V + f_{t-1}^Q\)。其中 \(A_{t-1} = \mathrm{Softmax}(\frac{f_{t-1}^Q(f_K)^\top}{\sqrt{C}})\) 是一个 attention map。
- Working memory:由最近 5 帧的密集 memory feature 组成。只有当新的 key feature 金额 value feature 的最大相似度小于 0.95,才会 insert working memory,如果 working memory 满了,最早的 memory feature 会被 push 进 long-term memory。
- Long-term memory:基于 XMem 通过记忆巩固来模拟人类记忆模型,对于 long-term memory keys,跟踪其累计的注意力权重,一旦 long-term memory 达到预定义的阈值,通过仅保留前 k 个标记来执行记忆稀疏化。
Training and Inference¶
略。
Experiments¶
Reference¶
- UCL 开源 | Spann3R:基于空间记忆,不估计相机参数也能实时重建
- 亲测 50 帧!无需内参!超越 Dust3r!Spann3r:无需优化对齐快速进行 3D 重建!
- 【论文笔记】Spann3R:基于 DUSt3R 的密集捕获数据增量式重建方法
最后更新:
2025年5月9日 15:51:31
创建日期: 2023年8月26日 15:00:56
创建日期: 2023年8月26日 15:00:56