VGGT¶
约 353 个字 预计阅读时间 1 分钟
Abstract
- paper:
 VGGT: Visual Geometry Grounded Transformer
VGGT: Visual Geometry Grounded Transformer - code: vggt
Introduction¶
问题导向
之前的 dust3r 等工作,需要使用视觉几何优化技术进行后处理的方法,并且耗时。
解决方案
VGGT 一次输入数百张图片,1s 之内预测所有图片的三维属性(相机的内参外参、pointmap、深度图、3D 点跟踪
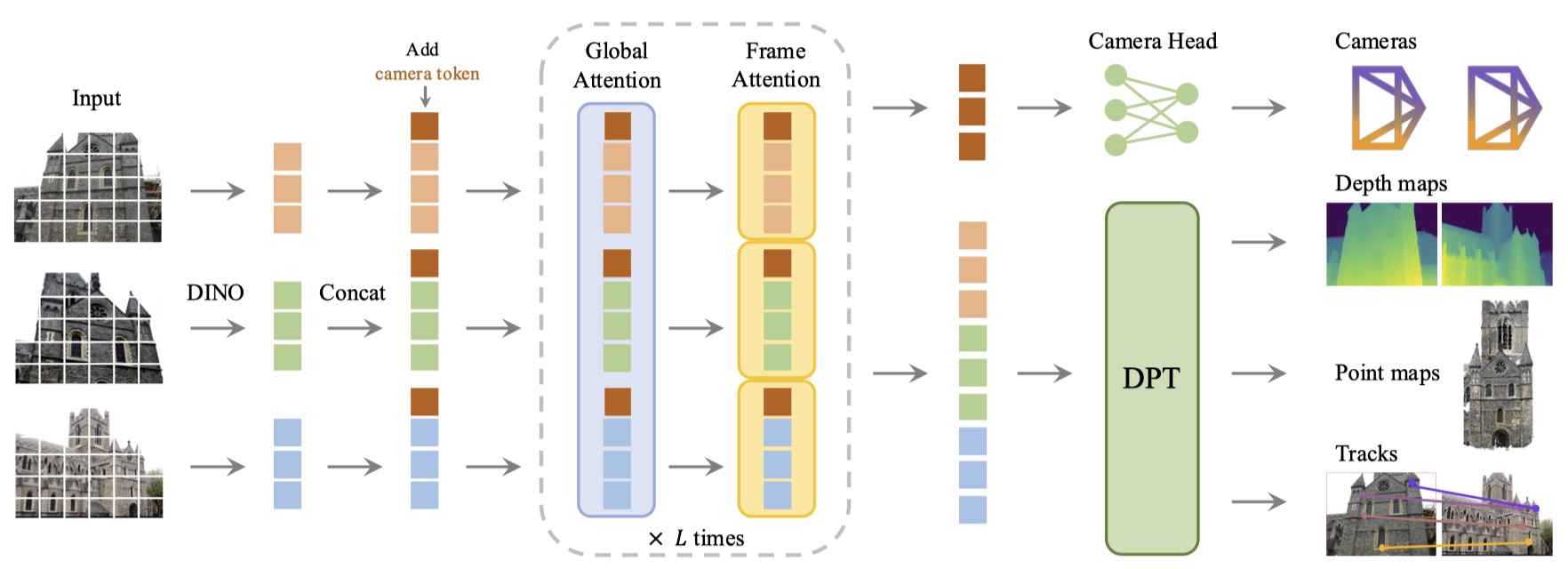
Method¶
Feature Backbone¶
- 每张图像首先通过 DINO 被分割成一组 K 个 token \(t_I\),然后,所有帧的 token 通过主网络结构进行处理,内部交替使用帧内和全局的 self-attention。
- Alternating-Attention,AA:每一层有两个注意力层:全局、帧间注意力。
Prediction Head¶
- camera parameters:4 个 self-attention layers + 一个全连接层
- dense map,point map 和 track feature:DPT layer
- tracking:采用 CoTracker2 结构
Training¶
- 使用一个多任务损失,前三个 loss 近似,tracking loss 需要尺度。
\[
\mathcal{L} = \mathcal{L}_{camera} + \mathcal{L}_{depth} + \mathcal{L}_{pmap} + \lambda \mathcal{L}_{track}
\]
- 真实坐标归一化:没有对输出的预测进行归一化,反而迫使从训练数据中学习归一化。
Experiments¶
Reference¶
- 论文学习及实验笔记之——《VGGT: Visual Geometry Grounded Transformer》
- VGGT| 基于视觉几何的 Transformer 网络 代码详解
- VGGT:CVPR2025 最佳论文,3D 基础模型来了!
最后更新:
2025年8月12日 15:58:16
创建日期: 2025年8月12日 15:58:16
创建日期: 2025年8月12日 15:58:16