DynaSLAM¶
约 1868 个字 4 张图片 预计阅读时间 6 分钟
Abstract
 DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
DynaSLAM: Tracking, Mapping and Inpainting in Dynamic ScenesINTRUDUCTION¶
在视觉 SLAM 中,动态物体会带来如下挑战:
- 如何检测图像中的动态物体,从而:
- 防止 tracking 算法使用动态物体上的匹配点对
- 防止 mapping 算法把移动物体加入 3D 地图中
- 怎么去补全 3D 地图中那些被移动物体挡住从而缺失了的部分。
DynaSLAM 是可以用于单目,双目,RGB-D 的动态 SLAM 系统,相当于是在 ORB-SLAM2 上加了一个前端的模块,上面的两个挑战,这篇论文都给出了对应的解决办法。
- 对于单目和双目:使用 CNN 进行像素分割,把图像中的人和车剔除,特征提取时就不会这些上面提取。
- 对于 RGB-D:结合多视角几何模型和深度学习(重点
! )
RELATED WORK¶
在这个部分作者还总结了一下目前动态 SLAM 的一些方法:
常规去除动态的外点:
- RANSAC
- robust cost function
对于基于特征的 SLAM:
- 通过把地图特征点投影到当前帧来检测场景中的变化
- 检测和追踪已知的 3D 动态点,比如人
- 使用深度边缘点,他有一个相关联权重可以用来表示其属于运动物体的概率
对于直接法 SLAM,他对动态物体更加敏感:
- 通过双目相机的场景流来检测移动物体
- 使用 RGB-D 光流分割动态物体
- 通过计算连续帧之间投影到同一平面的深度图的差别来找到静止的部分
- 计算连续 RGB 图像之间 intensity 的差别,像素分类通过对量化的深度图进行分割而完成?
上面列出关于特征法和直接法的方案都有一些问题没能解决:
- 不能估计一些保持静止的先验动态物体,比如静止的汽车,坐着的人
- 不能检测静态物体引起的变化,比如说被人拖动的椅子,或者被人丢飞的球。
而 DynaSLAM 不仅可以检测出正在移动的物体,还可以检测出一些“可被移动”的物体。
SYSTEM DESCRIPTION¶

Segmentation of Potentially Dynamic Content using a CNN¶
使用 MASK-RCNN 进行像素级分割,只用到语义信息。
Low-Cost Tracking¶
上一步中把动态特征点去除后,用剩下的静态点线求出一个相机的位姿。由于计算特征点的时候,特征点本就喜欢落在分割轮廓这种高梯度区域(可以找图片看一下,比如,人身体分出来的分割边界,后面就是背景,有一些遮挡关系,分割边界附近会是梯度变化大的区域,特征点本身就容易落在这种地方
Segmentation of Dynamic Content using Mask R-CNN and Multi-view Geometry¶
使用 MASK-RCNN 只能分割出先验的动态物体,但是不能找到那些“可以被移动”的物体,比如被人拿着的书,跟人一起移动的转椅等等。为了解决这种情况,就采用了下面的多视图几何的方法:
- 对于每一个输入帧,选择之前的和输入帧有最高重合度的多个关键帧(论文设置为 5 个
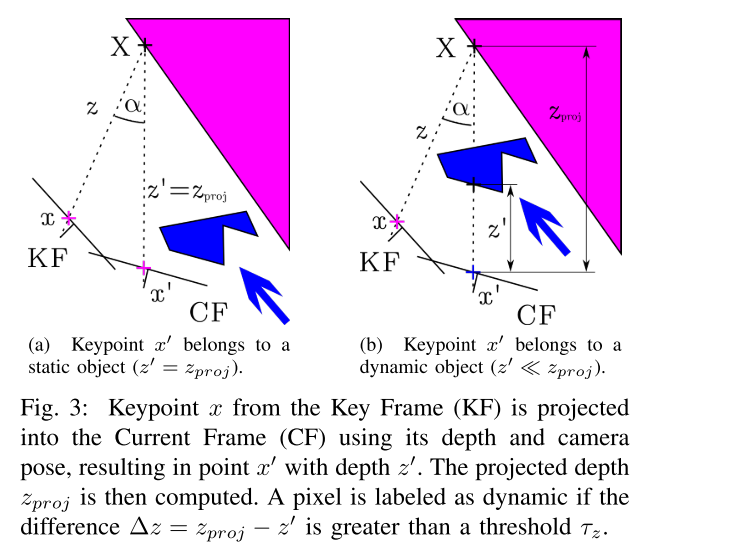
) ,这个重合度是通过考虑新的一帧和每个关键帧之间的距离和旋转来决定的。 - 把之前关键帧中的每个关键点 \(x\) 都投影到当前帧,得到关键点 \(x^\prime\) 和它们的投影深度 \(z_{proj}\)
- 对于每个关键点,它对应的 3D 点是 \(X\)。然后,计算 \(x\) 和 \(x^\prime\) 反投影之间的夹角,即视差角 \(\alpha\)。如果角度大于 30 度,这个点就有可能被遮挡,之后就会被忽略。比如在 TUM 数据集中,如果视差角大于 30 度,由于视角的不同,静态点就会被视为动态。
- 计算出关羽深度的重投影误差:\(\Delta z = z_{proj} - z^\prime\),\(z^\prime\) 是当前帧中还有的关键点的深度(测量值
) 。如果 \(\Delta z > \tau_z\),关键点 \(x^\prime\) 就会被视为动态物体。为了一个好的精度和召回率,通过最大化 \(0.7 * Presion + 0.3 * Recall\),将 \(\tau_z\) 定为 0.4m。
- 有一些被标记为动态的关键点位于移动物体的边界上,这可能会引起问题。为了避免这种情况,可以使用深度图像所提供的信息。如果一个关键点被设定为动态,但在深度图中它周围的区域有很大的方差,我们就把标签改为静态。
- 为了找到动态物体的所有像素点,在深度图的动态点周围进行区域增长算法。

这两种方法呈现出功能上的互补,所以最终取了两个 Mask 的并集,被分割的动态部分被从当前帧和地图中移除:
- 多视图几何:能识别出“可以被移动”的物体,但需要有多视图才能进行初始化。在图 4a 中看到,不仅检测到了图像前面的人,而且还检测到了他所拿的书和他所坐的椅子;但是远处的人并没有被检测到,原因有二:RGB-D 相机在测量远处物体的深度时会有困难;其次,可靠的特征位于确定的,因此是附近的图像部分。
- 深度学习:只能识别出先验的动态物体,但是没有初始化方面的问题。可以在图 4b 看到,只有两个人被检测为动态物体,而且分割也不太准确;而浮动的书会被留在图像中,并错误地成为三维地图的一部分。
Tracking and Mapping¶
这一步中,系统的输入是:RGB 图,深度图像,分割的 Mask。
在图像中提取出的ORB特征点都被标记为静态点,如果特征点落在了分割轮廓周围(高梯度区域
Background Inpainting¶
对于每一个被移除的动态物体,希望能用之前视图中的静态信息来补全丢失的背景信息(被动态物体遮挡了的部分
- 有些空隙没有对应关系,被留为空白
- 有些区域不能被补全,因为其对应的场景部分到目前还没出现在关键帧中
- 如果它出现了,但没有有效的深度信息。这些空隙也不能用几何方法来重建,而需要一种更复杂的涂抹技术。
从下面的图 5 可以看到大部分被分割的部分已经用来自静态背景的信息进行了适当的补全。

EXPERIMENTAL RESULTS¶
略。