Co-SLAM¶
约 713 个字 2 张图片 预计阅读时间 2 分钟
Abstract
 Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM Co-SLAM
Co-SLAMAbout INR¶
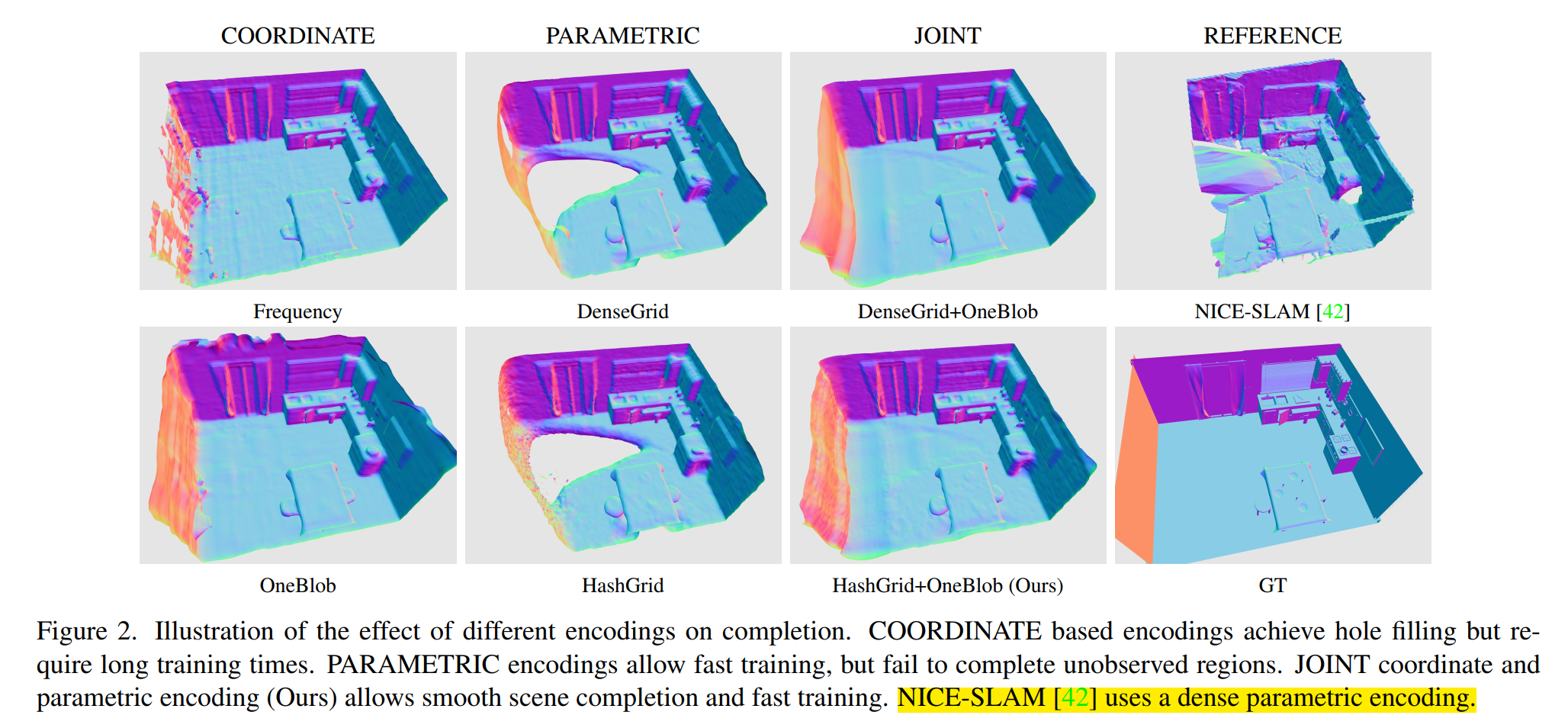
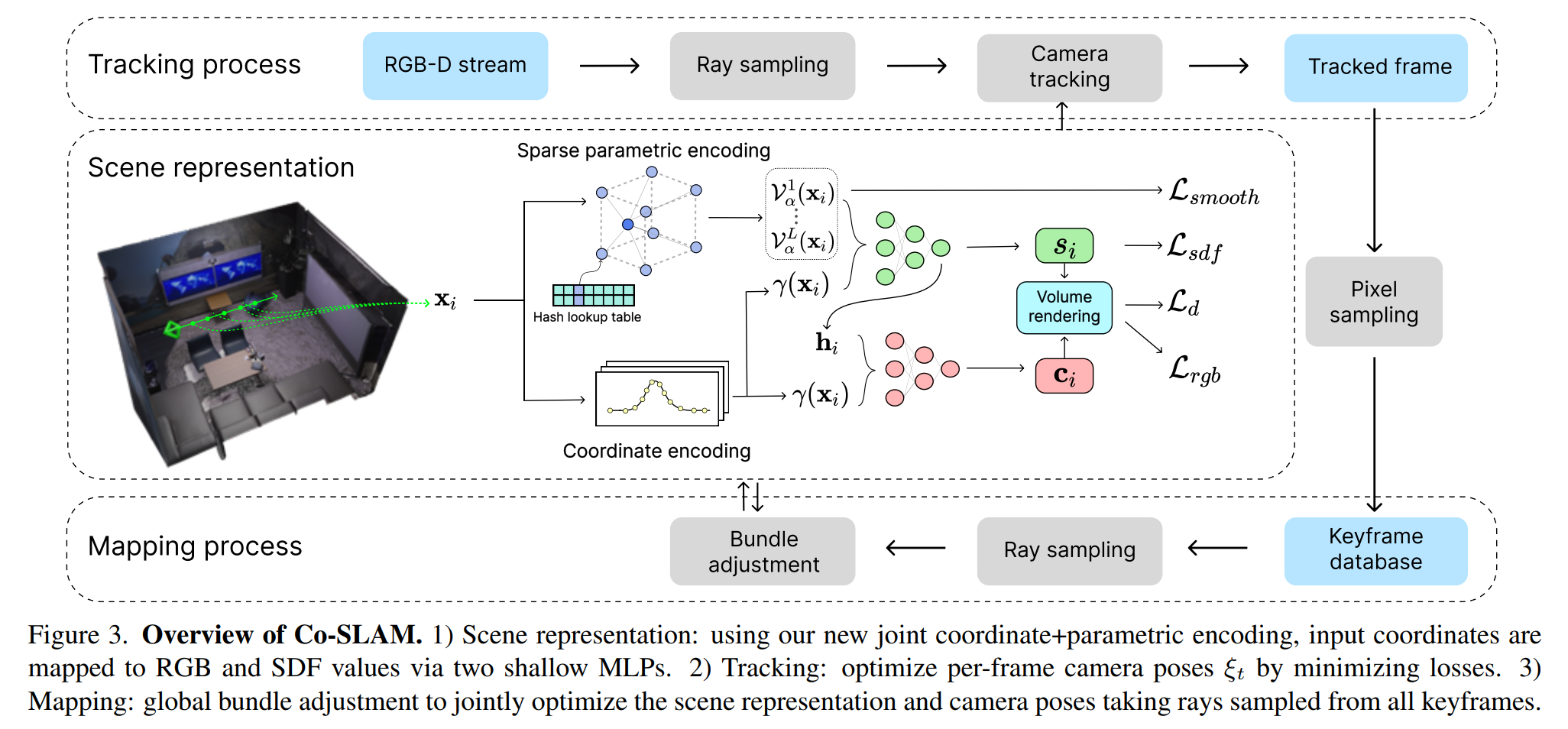
神经隐式表征 slam(implict neural representaton,INR)使用一个连续函数来表征图像或者三维 voxel,并用神经网络来逼近这个函数。Co-SLAM 也是这类工作,Co-SLAM 将场景表示为多分辨率哈希网格,以利用其较高的收敛速度和表示高频局部特征的能力。此外,Co-SLAM 还采用了 one-blob encoding,以促进未观察区域的表面一致性和完整性;在所有关键帧上进行 BA。
Related Work¶
稠密图视觉 SLAM ¶
传统采用 3D-3D ICP 求解,采用深度学习可以提升准确性和鲁棒性,但大部分的 pipeline 仍然采用传统方法。
INR¶
INR 在神经网络中编码三维图像,如具有代表性的 NeRF,采用了带有 MLP 的 coordinate encoding 通过体绘制进行场景重建,但是训练事件过长,后续有 parametric embedding 等工作,虽然增加了参数量,但是减少了训练时间。
Neural Implicit SLAM¶
iMAP 采用 MLP 在接近实时内同时追踪和建图,从而实现了 10 Hz tracking 和 2 Hz 建图。为了减少计算开销并提高可扩展性,NICE-SLAM 采用了多层特征网格来表示场景。然而,由于特征网格只进行局部更新,因此无法实现合理的 hole-filling。
Idea¶
- Joint Corrdinate and Parametric Encoding
- 基于坐标的表示方法受益于 MLP 的平滑一致性实验,能够得到高保真的重建结果,但是收敛太慢,而且会发生灾难性遗忘。
- 基于参数的表示方法提高了计算效率,但在平滑性和 hole-filling 上表现不好。
- Co-SLAM 采用了联合坐标和参数编码,适用 One-blob 编码,而不是将空间坐标嵌入多个频段,在 hashGrid 的多分辨率特征网络表征中使用 One-blob 编码,可以实现快速收敛和 online-slam 所需的 hole-filling。
- Depth and Color Rendering:通过对沿采样射线的预测值进行积分,呈现深度和色彩。
- Tracking and BA
- 目标函数:颜色和深度 loss 通过平方误差计算,
- Camera Tracking:相机到世界的变换矩阵 T,基于匀速恒定运动模型,然后选取当前帧内的 \(N_t\) (1024) 个像素,通过最小化目标函数优化位姿,而目标函数与相机外参有关。
- BA:在 Co-SLAM 中,不再需要存储完整的关键帧图像或关键帧选择。相反只存储代表每个关键帧的像素子集(约 5%
) 。为了进行联合优化,我们从全局关键帧列表中随机抽取 \(N_g\) 条射线,以优化场景表示和相机位姿。
Experiments¶