iMAP¶
约 969 个字 3 张图片 预计阅读时间 3 分钟
Abstract
 iMAP: Implicit Mapping and Positioning in Real-Time
iMAP: Implicit Mapping and Positioning in Real-TimeIdea¶
Intrdocution¶
- 第一个基于 RGB-D 相机,用 MLP 做场景表征实时SLAM 系统
- 相比于传统的 TSDF 场景表征方法,iMAP 可以重建出未被观察到的地方
- 隐式场景表征可以用来做相机位姿估计,但都是离线形式,计算量大,iMAP 使用深度图像能达到实时效果
- 持续学习会遇到灾难性遗忘,iMAP 采用 replay-based approach,将先前的结果缓存
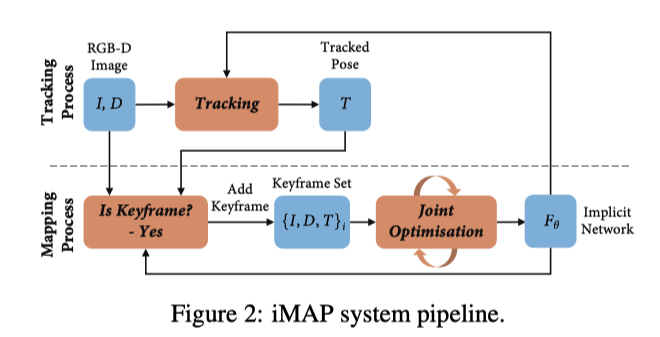
Implicit Scene Neural Network¶
- 借鉴 NeRF,用 MLP 将 3D 坐标点转换成颜色和体积密度值:\(\bold{p}=(x,y,z),F_\theta(\bold{p})=(\bold{c}, \rho)\)
- 不考虑视角方向(不需要对镜面反射建模)
Depth and Colour Rendering¶
- 通过 scene network 来从指定视角得到深度和颜色图像
- 输入是相机位姿 \(T_{WC}\) 和像素坐标 \([u,v]\),先反投影到世界坐标系 :
\[\bold{r}=T_{WC}K^{-1}[u,v]\]
- 然后在视角射线上采样:
\[\bold{p}_i=d_i \bold{r} \ \ \ \ \ d_i \in \{d_1, ..., d_N\}\]
- 查询场景网络之前得到的颜色和体积密度:
\[(\bold{c}_i, \rho_i) = F_\theta(\bold{p}_i)\]
- 将体积密度转换为占据概率 occupancy probability:
\[
\delta_i = d_{i+1} - d_i \\
o_i = 1 - \exp(-\rho_i \delta_i) \\
w_i = o_i \prod_{j=1}^{i-1}(1-o_j)
\]
- 得到深度和颜色:
\[
\hat{D}[u,v] = \sum_{i=1}^{N}w_i d_i \\
\hat{I}[u,v] = \sum_{i=1}^{N}w_i \bold{c}_i
\]
- 计算深度的方差:
\[
\hat{D}_{var}[u,v] = \sum_{i=1}^{N}w_i (d_i - \hat{D}[u,v])^2
\]
Joint optimisation¶
-
用关键帧集合,针对网络参数和相机位姿做联合优化。Adam 优化器,loss 是光度误差和几何误差的加权
-
光度误差 photometric error:
\[
e_i^p[u, v]=\left | I_i[u,v] - \hat{I}_i[u,v] \right | \\
\\
L_p = \frac{1}{M} \sum_{i=1}^{W} \sum_{(u,v) \in s_i} e_i^p[u, v]
\]
- 几何误差 geometric error(使用到深度方差
) :
\[
L_g = \frac{1}{M} \sum_{i=1}^{W} \sum_{(u,v) \in s_i} \frac{e_i^g[u,v]}{\sqrt{\hat{D}_{var}[u,v]}}
\]
- Adam 优化器,对光度误差添加一个权重 \(\lambda\):
\[
\min_{\theta,\{T_i\}}(L_g + \lambda_p L_p)
\]
- 上面都是 Mapping 阶段,Tracking 阶段与 Mapping 并行,但是频率更高,针对 latest frame,固定场景网络,使用之前的 loss 和优化器优化位姿
Keyframe Selection¶
- 考虑计算复杂度和图像冗余度,基于 information gain 选取关键帧
- 第一帧 一定被选取,用作网络初始化和世界坐标系的固定
- 每新增一个关键帧,保存一次 network 作为 snapshot,用于 replay(防止 catastrophic forgetting 的缓存机制)
-
后续关键帧的选取方法是,与 snapshot 做比较,是否观察到了新区域
- 在 snapshot 和 frame 随机选取 s 个像素点
- 比较深度值差一,计算如下分数,然后与阈值做比较,小于就加入关键帧
\[ P=\frac{1}{\left | s \right | } \sum_{(u,v) \in s} (\frac{\left | D[u,v] - \hat{D}[u,v] \right | }{D[u,v]} < t_D) \]
Active Sampling¶
-
为了减少计算复杂度,iMAP 分别对像素点、关键帧都做了 Active Sampling
- image active sampling:对图像随机选点,选取方法是先分块,先均匀采样,分块求 loss,计算每一块的权重,然后根据权重采样
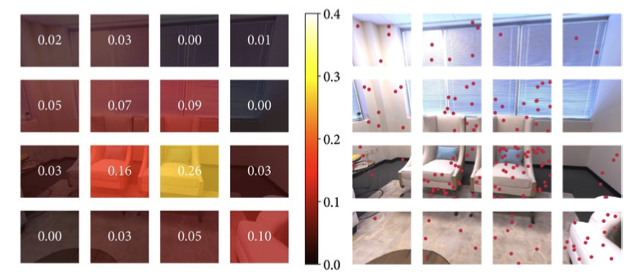
- keyframe active sampling:为了限制联合优化的计算复杂度,每次迭代只选三个关键帧。同上,也是计算 loss 在分配权重

Experiments¶
我们对模拟序列和真实序列进行实验。对于重建评估,我们使用副本数据集 [29],对真实房间规模的环境进行高质量 3D 重建,包括 5 个办公室和 3 个公寓。对于每个副本场景,我们渲染 2000 个 RGB-D 帧的随机轨迹。对于原始相机录制,我们使用手持 Microsoft Azure Kinect 在各种环境中捕获 RGB-D 视频,并在 TUM RGB-D 数据集 [30] 上进行测试以评估相机跟踪。
- 对于重建评估,数据集是 Replica 的 5 offices 和 3 apartments
- 对于原始相机录制,使用手持 Microsoft Azure Kinect 在各种环境中捕获 RGB-D 视频,并在 TUM RGB-D 上进行测试以评估相机跟踪。