DeepV2D¶
约 408 个字 3 张图片 预计阅读时间 1 分钟
Abstract
 DeepV2D: Video to Depth with Differentiable Structure from Motion
DeepV2D: Video to Depth with Differentiable Structure from MotionIdea¶
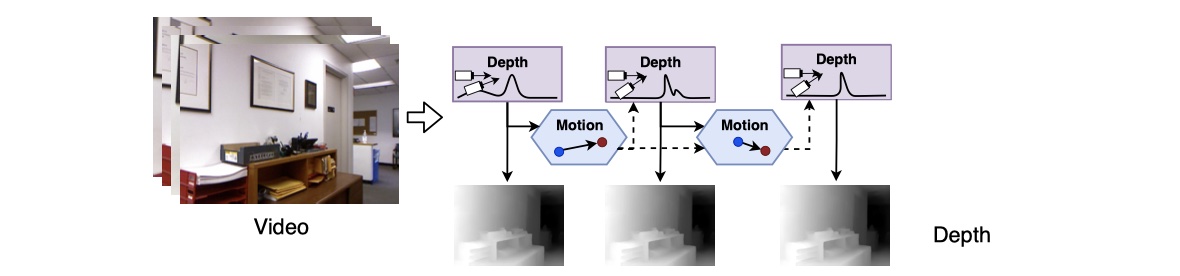
- 通过视频序列预测进行深度估计,分为两模块:深度模块和运动模块;
- 深度模块将相机运动作为输入,输出更新的深度预测;运动模块将深度作为输入,输出运动矫正项;
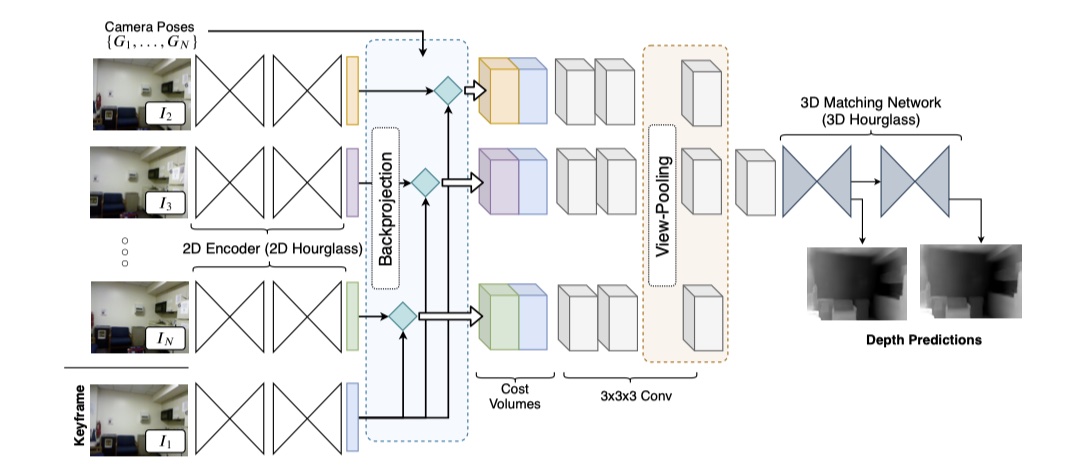
- 深度模块:
- 2D 特征提取:提取从输入图片学习到的特征;
- 反投影代价容量函数:设计一种代价容量函数,将 \(I_1\) 作为关键帧,其余 \(I_{2,...,n}\) 帧被用于代价容量函数;
- 3D 立体匹配:\(N-1\) 代价容量函数的集合首先通过 3D 卷积层后再进行立体匹配,然后通过平均 \(N-1\) 个容量函数来执行视图池化,聚合帧的信息;
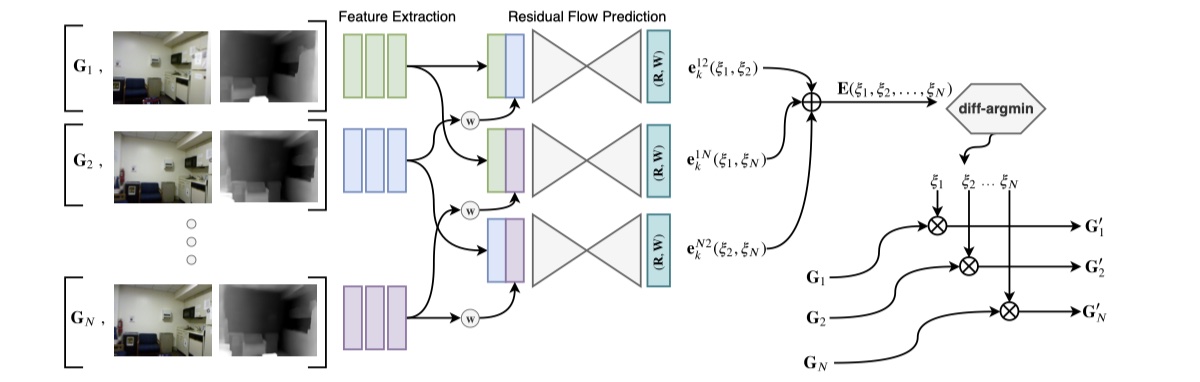
- 运动模块:
- 初始化:使用一个网络预测初始姿态估计,选择一帧作为关键帧。通过将关键帧姿态设置为单位矩阵来初始化姿态,然后预测关键帧与视频中每个其他帧之间的相对运动;
- 特征提取:特征提取器将每一帧映射到一个密集的特征映射,权重在所有帧之间共享;
- 误差项
- 优化目标
- 全局姿态优化
- 关键帧姿态优化
- LS- 优化层
- 总系统:采用两种初始化策略,自初始化使用恒定深度图初始化 DeepV2D;单幅图像初始化使用单幅图像深度网络的输出进行初始化;
- 监督损失函数:
- 深度监督
- 运动监督
- 总损失