LMDeploy 大模型量化部署实践 ¶
约 1186 个字 66 行代码 7 张图片 预计阅读时间 5 分钟
Abstract
大模型部署背景 ¶
模型部署 ¶
- 定义
- 将训练好的模型在特定软硬件环境中启动的过程,使模型能够接受输入并返回预测结果
- 为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩和硬件加速
- 产品形态
- 云端、边缘计算端、移动端
- 计算设备
- CPU、GPU、TPU、NPU 等
大模型特点 ¶
- 内存开销巨大
- 庞大参数量,7B 模型仅权重就需要 14+G 内存
- 采用自回归生成 token,需要缓存 Attention 的 k/v,带来巨大的内存开销
- 动态 shape
- 请求数不固定
- Token 逐个生成,且数量不定
- 相对视觉模型,LLM 结构简单
- Transformers 结构,大部分是 decoder-only
大模型部署挑战 ¶
- 设备
- 如何应对巨大的存储问题?低存储设备(消费级显卡、手机等)如何部署?
- 推理
- 如何加速 token 的生成速度
- 如何解决动态 shape,让推理可以不间断
- 如何有效监督和利用内存
- 服务
- 如何提升系统整体吞吐量?
- 对于个体用户,如何降低响应时间?
大模型部署方案 ¶
- 技术点
- 模型并行
- 低比特量化
- Page Attention
- transformer 计算和访存优化
- Continuous Batch
- ...
- 方案
- huggingface Transformers
- 专门的推理加速框架
- 云端
- lmdeploy
- vllm
- tensorrt-llm
- deepspeed
- 移动端
- llama.cpp
- mlc-llm
- ...
LMDeploy 简介 ¶
LMDeploy 是 LLM 在 Nvidia 设备上部署的全流程解决方案,包括模型轻量化、推理、服务。
核心功能 ¶
量化 ¶
- 为什么 Weight Only 量化?
- 4bit Weight Only 量化,将 FP16 的模型权重量化为 INT4,访存量直接降为 FP16 的模型 1/4,大幅降低了访存成本,提高 Decoding 的速度。
- 加速的同时还节省显存,同样的设备能够支持更大的模型以及更长的对话长度。
- 如何做 Weight Only 量化?
- LMDeploy 使用 MIT HAN LAB 开源的 AWQ 算法,量化为 4bit 模型
- 推理时,先把 4bit 权重,反量化回 FP16(在 Kernel 内部进行,从 Global Memory 读取时仍是 4bit
) ,依旧使用的是 FP16 计算 - 想较于社区使用最多的 GPTQ 算法,AWQ 的推理速度更快,量化时间更短
推理引擎 TurboMind ¶
- 持续批处理

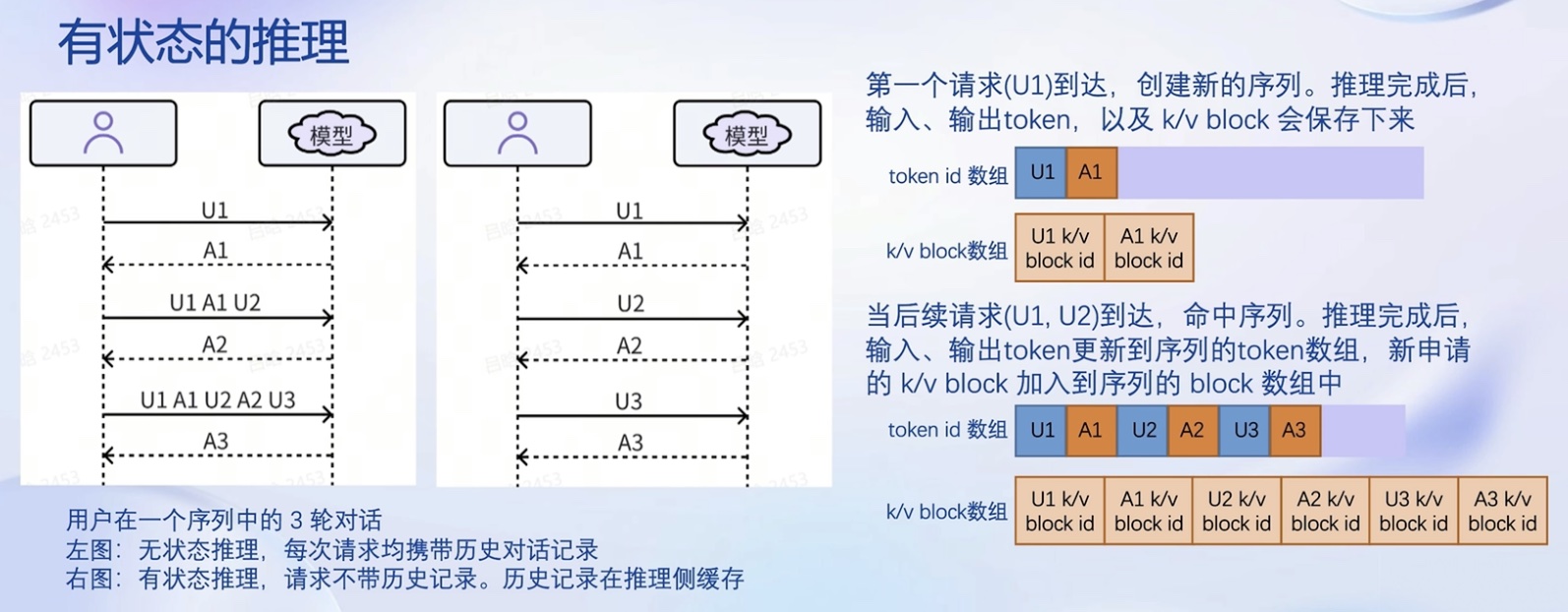
- 有状态的推理
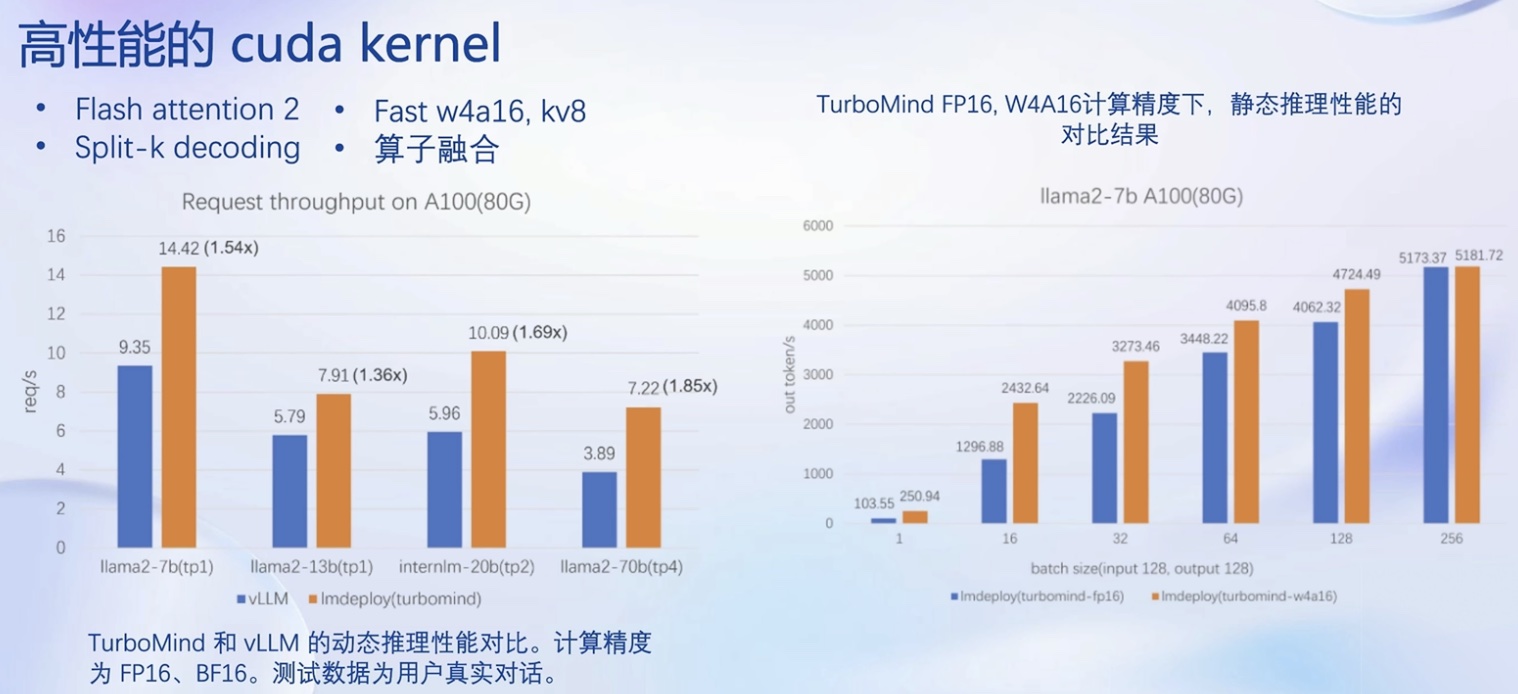
- 高性能 cuda Kernel
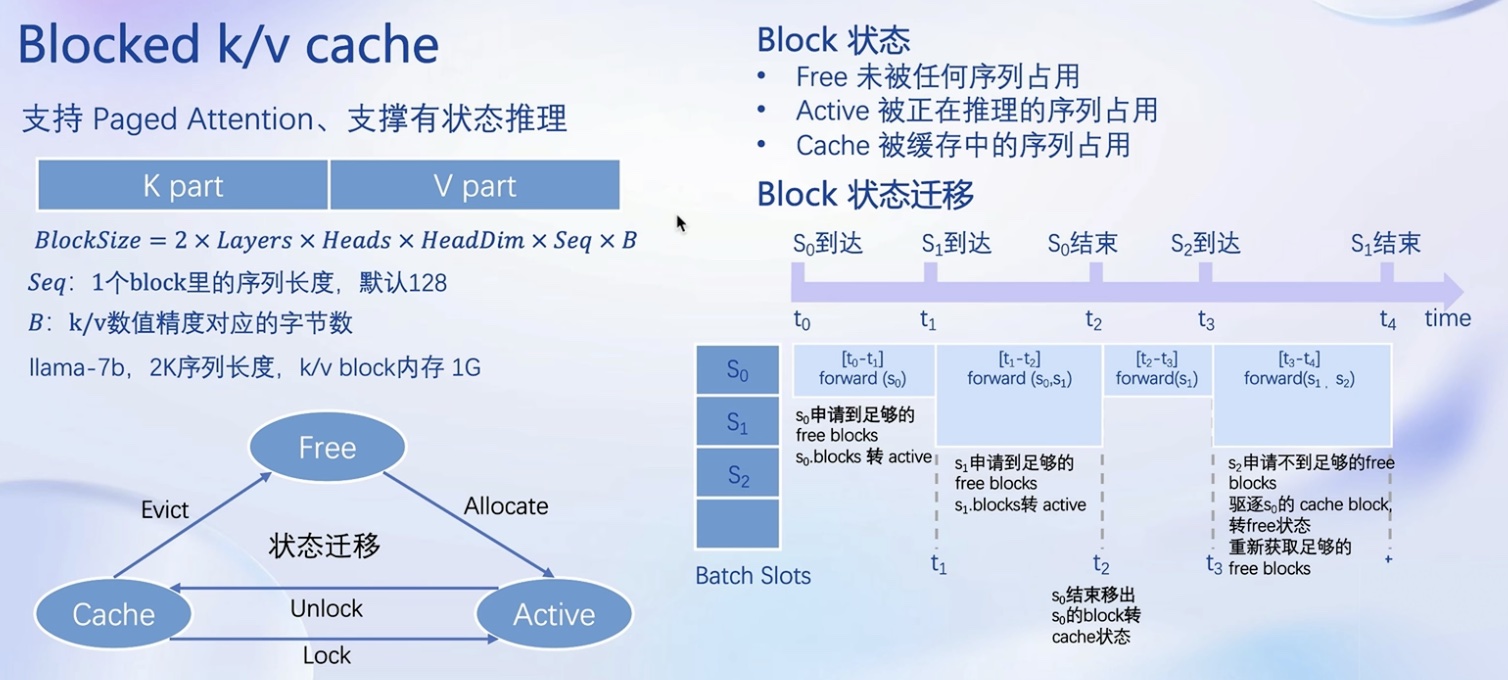
- Blocked k/v cache
推理服务 api server ¶
lmdeploy serve api_server InternLM/internlm-chat-7b \
--model-name internlm-chat-7b --server-port 8080
服务部署 ¶
模型转换 ¶
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式,目前支持在线转换和离线转换两种形式。在线转换可以直接加载 Huggingface 模型,离线转换需需要先保存模型再加载。
在线转换 ¶
lmdeploy 支持直接读取 Huggingface 模型权重,目前共支持三种类型:
- 在 huggingface.co 上面通过 lmdeploy 量化的模型,如 llama2-70b-4bit, internlm-chat-20b-4bit
- huggingface.co 上面其他 LM 模型,如 Qwen/Qwen-7B-Chat
在线转换
- 加载 Huggingface 模型
# 需要能访问 Huggingface 的网络环境
lmdeploy chat turbomind internlm/internlm-chat-20b-4bit --model-name internlm-chat-20b
lmdeploy chat turbomind Qwen/Qwen-7B-Chat --model-name qwen-7b
- 直接启动本地的 Huggingface 模型
离线转换 ¶
离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式,执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。
TurboMind 推理 + 命令行本地对话 ¶
模型转换完成后,我们就具备了使用模型推理的条件,接下来就可以进行真正的模型推理环节。
TurboMind 推理 +API 服务 ¶
上面直接用命令行启动 Client,接下来运用 lmdepoy 进行服务化。
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1
新开一个窗口,执行下面的命令或直接打开 http://{host}:23333
Web Demo 对话 ¶
TurboMind 服务作为后端 ¶
启动作为前端的 Gradio
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api True
TurboMind 推理作为后端 ¶
TurboMind 推理 +Python 代码集成 ¶
from lmdeploy import turbomind as tm
# load model
model_path = "/root/share/temp/model_repos/internlm-chat-7b/"
tm_model = tm.TurboMind.from_pretrained(model_path, model_name='internlm-chat-20b')
generator = tm_model.create_instance()
# process query
query = "你好啊兄嘚"
prompt = tm_model.model.get_prompt(query)
input_ids = tm_model.tokenizer.encode(prompt)
# inference
for outputs in generator.stream_infer(
session_id=0,
input_ids=[input_ids]):
res, tokens = outputs[0]
response = tm_model.tokenizer.decode(res.tolist())
print(response)
模型量化 ¶
量化是一种以参数或计算中间结果精度下降换空间节省(以及同时带来的性能提升)的策略。
KV Cache 量化 ¶
- 计算 minmax。通过计算给定输入样本在每一层不同位置计算结果的统计情况。
# 计算 minmax
lmdeploy lite calibrate \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir ./quant_output
- 通过 minmax 获取量化参数。获取每一层的 KV 中心值(zp)和缩放值(scale
) 。
# 通过 minmax 获取量化参数
lmdeploy lite kv_qparams \
--work_dir ./quant_output \
--turbomind_dir workspace/triton_models/weights/ \
--kv_sym False \
--num_tp 1
- 修改配置。修改
weights/config.ini文件。
W4A16 量化 ¶
W4A16 中的 A 指 Activation,保持 FP16,只对参数进行 4bits 量化。
- 同 KV Cache 量化,计算 minmax。
- 量化权重参数。利用第一步得到的统计值对参数进行量化。
- 缩放参数
- 整体量化
# 量化权重模型
lmdeploy lite auto_awq \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--w_bits 4 \
--w_group_size 128 \
--work_dir ./quant_output
- 转换成 TurboMind 格式。
# 转换模型的layout,存放在默认路径 ./workspace 下
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128
作业 ¶
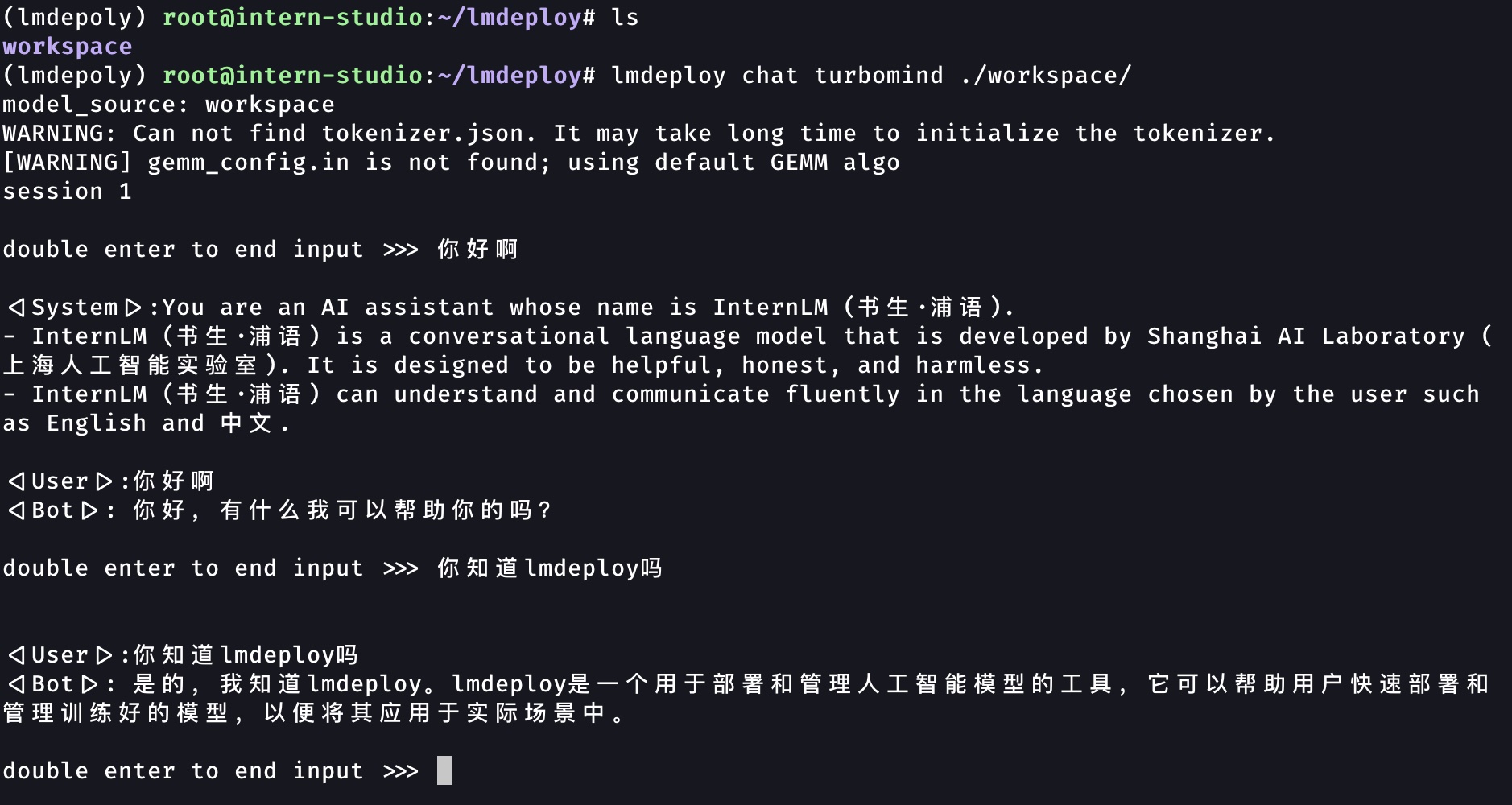
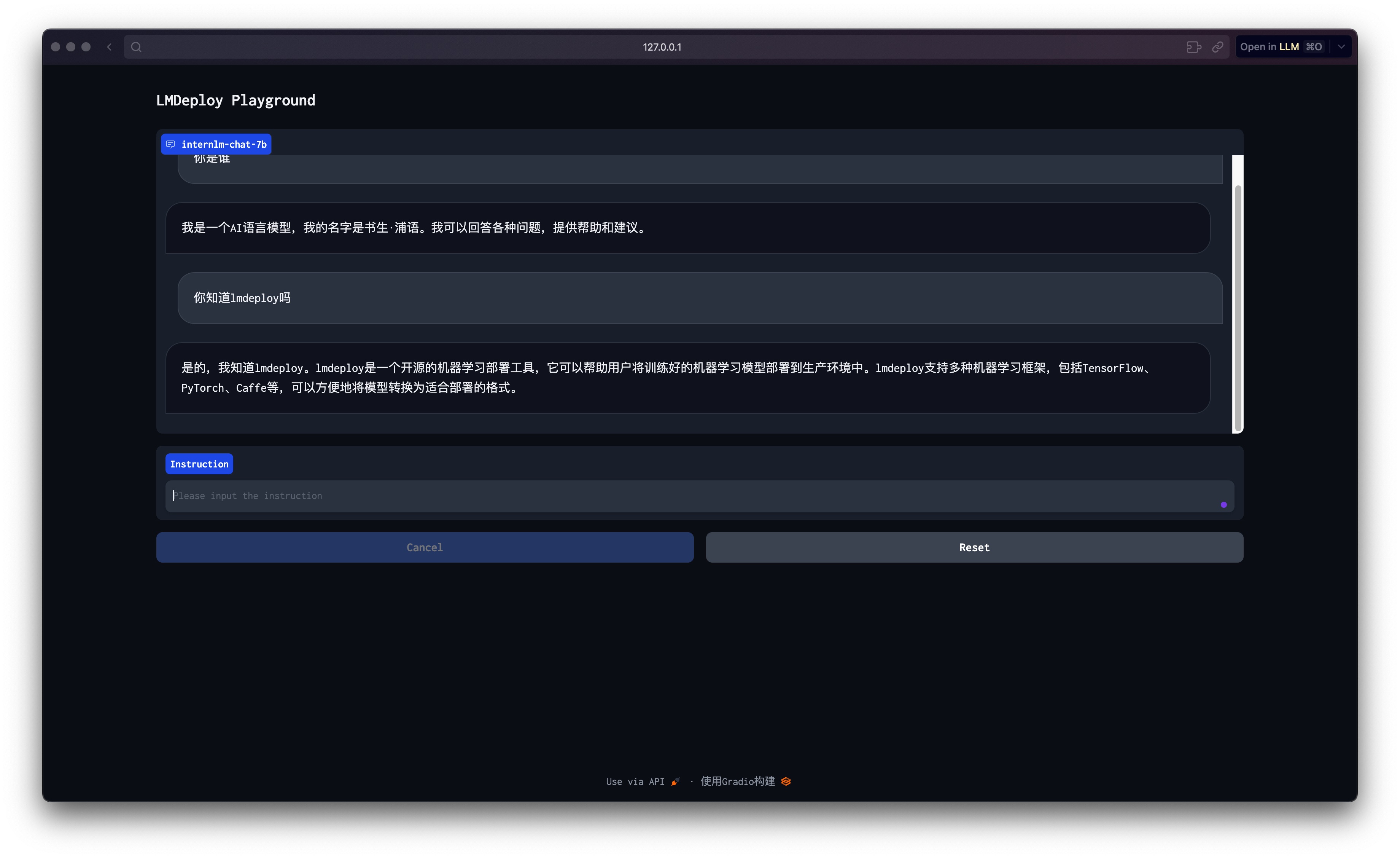
使用 LMDeploy 以本地对话、网页 Gradio、API 服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图)
- 本地对话
- Web Gradio
- API 服务