Attention 机制 ¶
约 2743 个字 7 张图片 预计阅读时间 9 分钟
Abstract
- 对于 RNN 中存在的信息瓶颈问题,注意力机制可以很好地解决这个问题。
- 本文将介绍 Encoder-Decoder、Seq2Seq 以及 Attention 机制。
Encoder-Decoder¶
Encoder-Decoder 模型主要是 NLP 领域里的概念。它并不特值某种具体的算法,而是一类算法的统称。Encoder-Decoder 算是一个通用的框架,在这个框架下可以使用不同的算法来解决不同的任务。
Encoder-Decoder 框架很好地诠释了机器学习的核心思路:
- Encoder 又称编码器,它的作用就是『将现实问题转化为数学问题
』 。 - Decoder 又称解码器,它的作用就是『求解数学问题,并转化为现实世界的解决方案
』 。
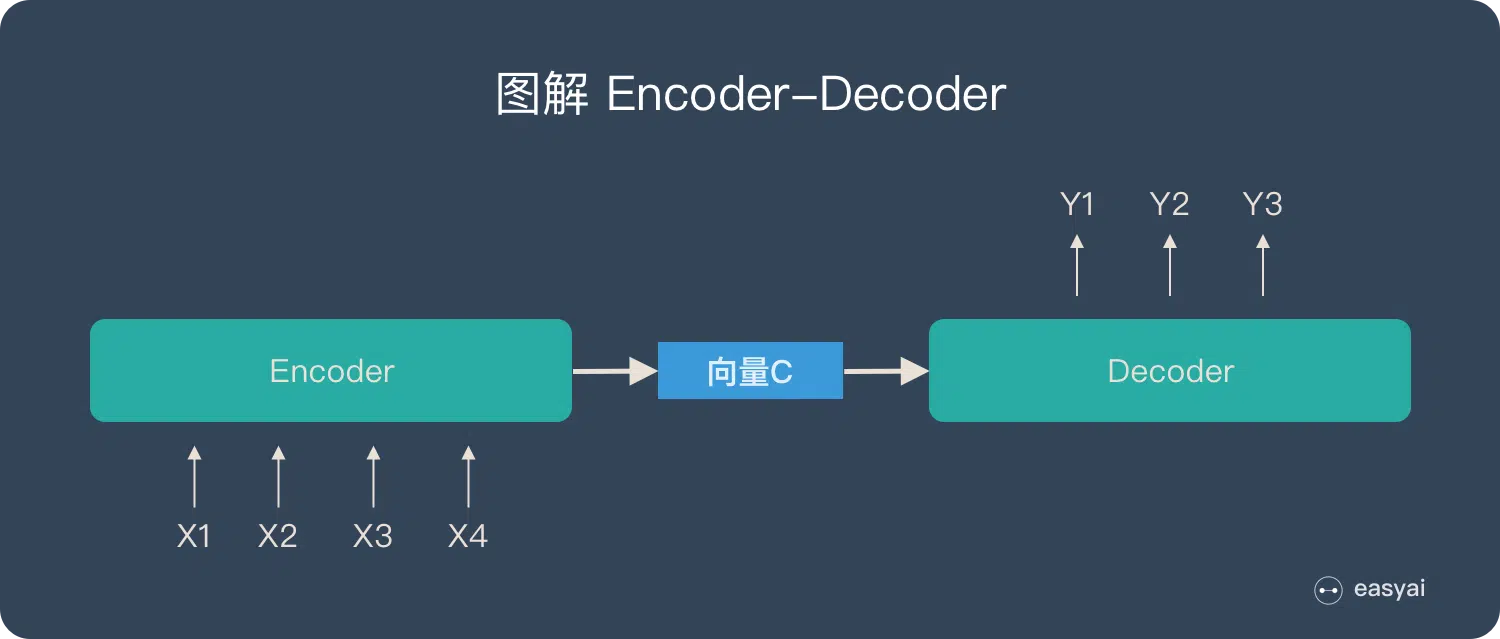
关于 Encoder-Decoder:
- 不论输入和输出的长度是什么,中间的向量 c的长度都是固定的(这也是它的缺陷
) 。 - 根据不同的任务可以选择不同的编码器和解码器(可以是一个 RNN,但通常是其变种 LSTM 或者 GRU
) 。
Encoder-Decoder 的缺陷
为了便于理解,我们类比为「压缩 - 解压」的过程:
将一张 800X800 像素的图片压缩成 100KB,看上去还比较清晰。再将一张 3000X3000 像素的图片也压缩到 100KB,看上去就模糊了。
Encoder-Decoder 就是类似的问题:当输入信息太长时,会丢失掉一些信息。
Seq2Seq¶
概述 ¶
Seq2Seq(是 Sequence to Sequence 的缩写
如上图:输入了 6 个汉字,输出了 3 个英文单词。输入和输出的长度不同。
Seq2Seq 和 Encoder-Decoder 的关系 ¶
Seq2Seq(强调目的)不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。
而 Seq2Seq 使用的具体方法基本都属于 Encoder-Decoder 模型(强调方法)的范畴。
总结一下的话:
- Seq2Seq 属于 Encoder-Decoder 的大范畴
- Seq2Seq 更强调目的,Encoder-Decoder 更强调方法
Attention¶
本质 ¶
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点
Attention 机制最早是在计算机视觉里应用的,随后在 NLP 领域也开始应用了,真正发扬光大是在 NLP 领域,因为 2018 年 BERT 和 GPT 的效果出奇的好,进而走红。而 Transformer 和 Attention 这些核心开始被大家重点关注。
如果用图来表达 Attention 的位置大致是下面的样子:

三大优点 ¶
之所以要引入 Attention 机制,主要是 3 个原因:
- 参数少:模型复杂度更 CNN、RNN 相比,复杂度更小,参数也更少。对算力的要求也就更少。
- 速度快:Attention 解决了 RNN 不能并行计算的问题。Attention 机制每一步计算不依赖于上一步的计算结果,因此可以和 CNN 一样并行处理。
- 效果好:在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
原理 ¶
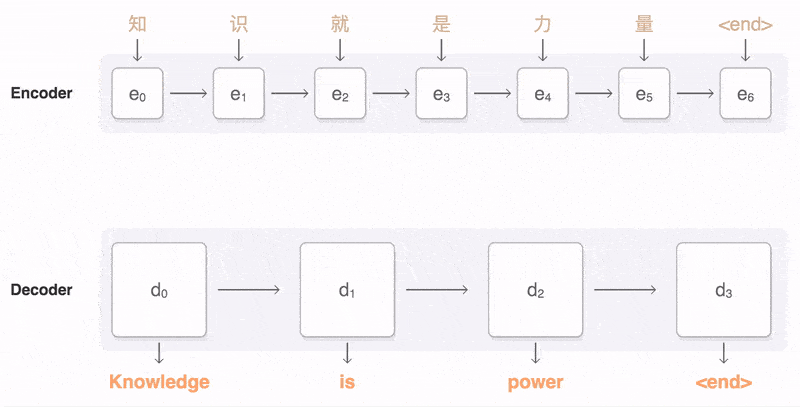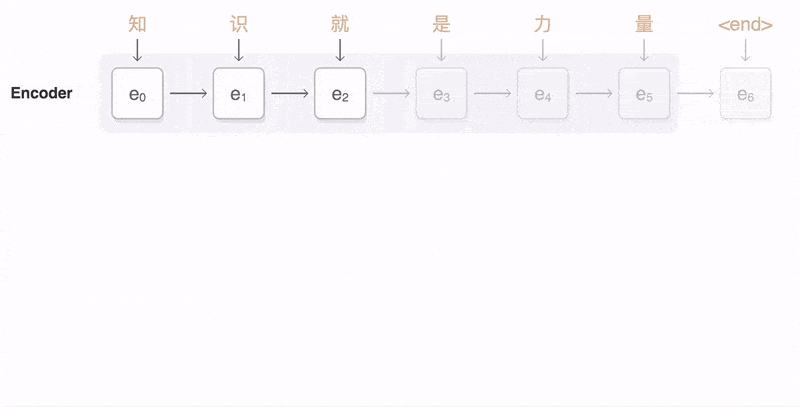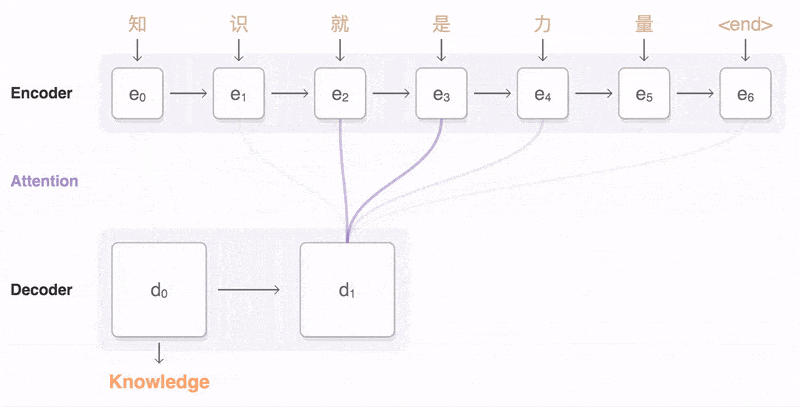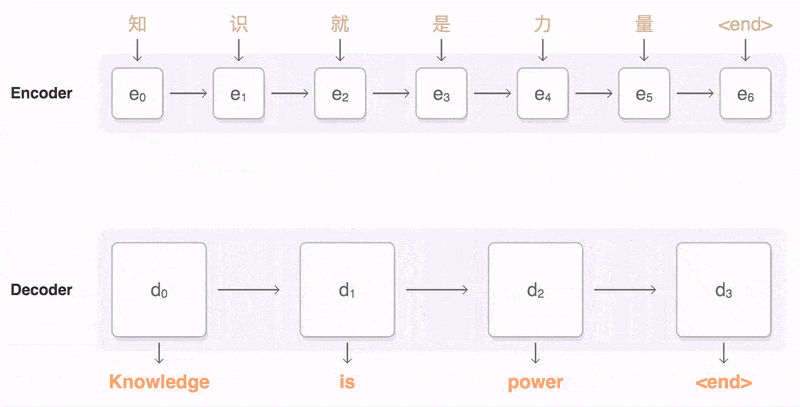
下面的动图演示了 attention 引入 Encoder-Decoder 框架下,完成机器翻译任务的大致流程。

但是,Attention 并不一定要在 Encoder-Decoder 框架下使用的,他是可以脱离 Encoder-Decoder 框架的。
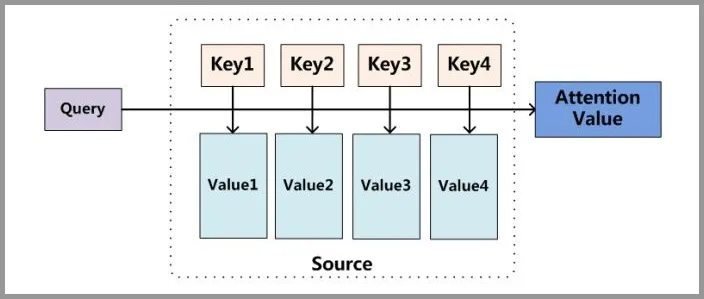
Attention 原理分为 3 步:
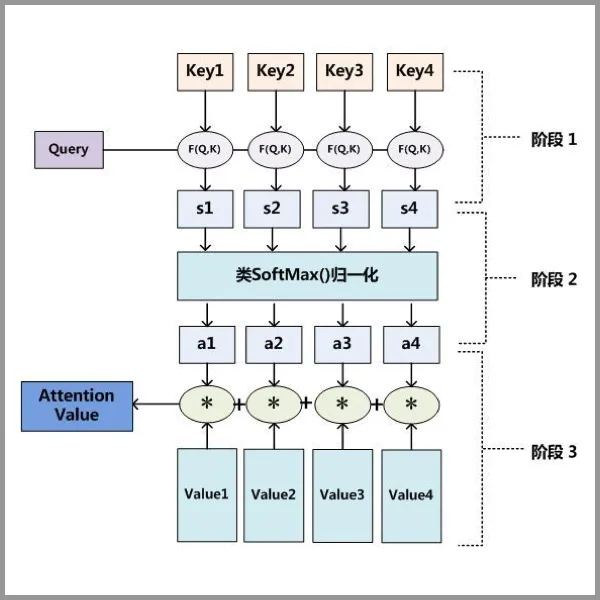
- query 和 key 进行相似度计算,得到权值
- 将权值进行归一化,得到直接可用的权重
- 将权重和 value 进行加权求和
从上面的建模,可以大致感受到 Attention 的思路简单,四个字“带权求和”,大道至简。
N 种类型 ¶
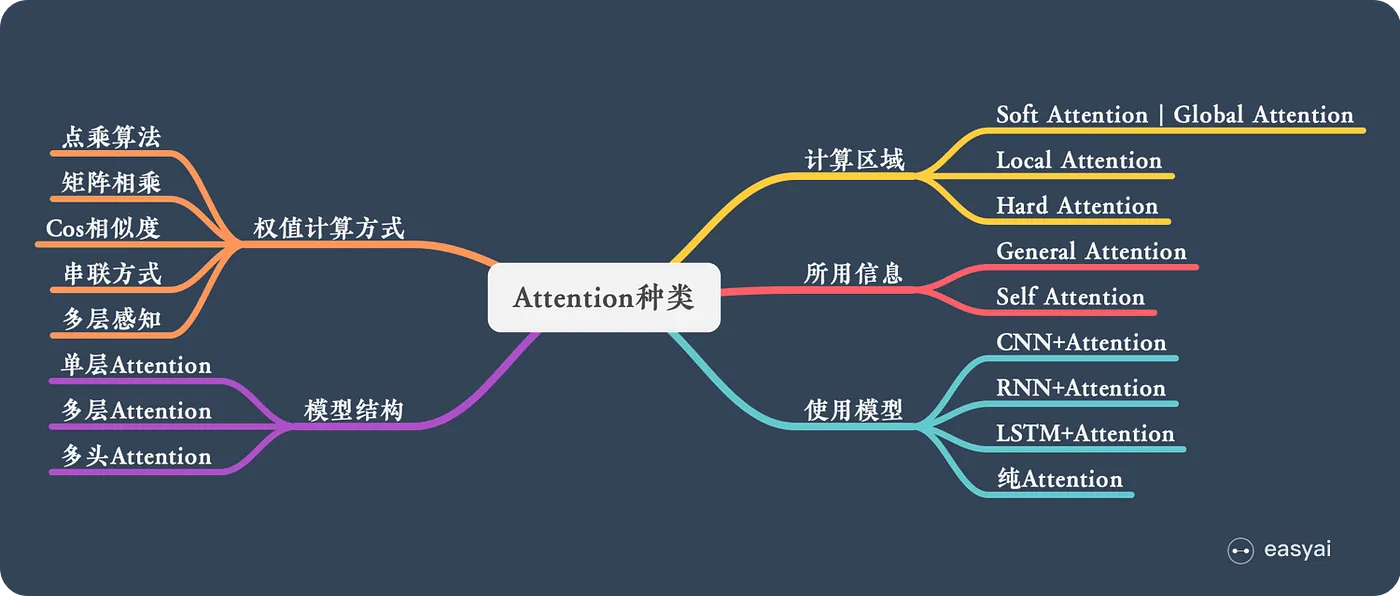
计算区域 ¶
- Soft Attention,这是比较常见的 Attention 方式,对所有 key 求权重概率,每个 key 都有一个对应的权重,是一种全局的计算方式(也可以叫 Global Attention
) 。这种方式比较理性,参考了所有 key 的内容,再进行加权。但是计算量可能会比较大一些。 - Hard Attention,这种方式是直接精准定位到某个 key,其余 key 就都不管了,相当于这个 key 的概率是 1,其余 key 的概率全部是 0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练
。 (或者使用 gumbel softmax 之类的) - Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用 Hard 方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用 Soft 方式来算 Attention。
所用信息 ¶
假设我们要对一段原文计算 Attention,这里原文指的是我们要做 attention 的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息。
- General Attention,这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query 一般包含了额外信息,根据外部 query 对原文进行对齐。
General Attention
比如在阅读理解任务中,需要构建问题和文章的关联,假设现在 baseline 是,对问题计算出一个问题向量 q,把这个 q 和所有的文章词向量拼接起来,输入到 LSTM 中进行建模。那么在这个模型中,文章所有词向量共享同一个问题向量,现在我们想让文章每一步的词向量都有一个不同的问题向量,也就是,在每一步使用文章在该步下的词向量对问题来算 attention,这里问题属于原文,文章词向量就属于外部信息。
- Local Attention,这种方式只使用内部信息,key 和 value 以及 query 只和输入原文有关,在 self attention 中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行 Attention 计算,相当于寻找原文内部的关系。
Local Attention
还是举阅读理解任务的例子,上面的 baseline 中提到,对问题计算出一个向量 q,那么这里也可以用上 attention,只用问题自身的信息去做 attention,而不引入文章信息。
结构层次 ¶
结构方面根据是否划分层次关系,分为单层 attention,多层 attention 和 多头 attention:
-
单层 Attention,这是比较普遍的做法,用一个 query 对一段原文进行一次 attention。
-
多层 Attention,一般用于文本具有层次关系的模型,假设我们把一个 document 划分成多个句子,在第一层,我们分别对每个句子使用 attention 计算出一个句向量(也就是单层 attention
) ;在第二层,我们对所有句向量再做 attention 计算出一个文档向量(也是一个单层 attention) ,最后再用这个文档向量去做任务。 -
多头 Attention,这是 Attention is All You Need 中提到的 multi-head attention,用到了多个 query 对一段原文进行了多次 attention,每个 query 都关注到原文的不同部分,相当于重复做多次单层 attention:
最后再把这些结果拼接起来:
模型方面 ¶
从模型上看,Attention 一般用在 CNN 和 LSTM 上,也可以直接进行纯 Attention 计算。
- CNN + Attention
CNN 的卷积操作可以提取重要特征,我觉得这也算是 Attention 的思想,但是 CNN 的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。另外,Max Pooling 直接提取数值最大的特征,也像是 hard attention 的思想,直接选中某个特征。
CNN 上加 Attention 可以加在这几方面:
a. 在卷积操作前做 attention,比如 Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行 attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。 b. 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。 c. 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
- LSTM+Attention
LSTM 内部有 Gate 机制,其中 input gate 选择哪些当前信息进行输入,forget gate 选择遗忘哪些过去信息,我觉得这算是一定程度的 Attention 了,而且号称可以解决长期依赖问题,实际上 LSTM 需要一步一步去捕捉序列信息,在长文本上的表现是会随着 step 增加而慢慢衰减,难以保留全部的有用信息。
LSTM 通常需要得到一个向量,再去做任务,常用方式有:
a. 直接使用最后的 hidden state(可能会损失一定的前文信息,难以表达全文) b. 对所有step下的hidden state进行等权平均(对所有step一视同仁)。 c. Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
- 纯 Attention
Attention is all you need,没有用到 CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算 attention。
相似度计算方式 ¶
在做 attention 的时候,我们需要计算 query 和某个 key 的分数(相似度
- 点乘:\(score(q,k)=q^\top k\)
- 矩阵相乘:\(score(q,k)=q^\top Wk\)
- 余弦相似度:\(score(q,k)=\frac{q^\top k}{\|q\| \cdot \|k\|}\)
- 串联方式,把 q 和 k 拼接起来:\(score(q,k)=W[q;k]\)
- 多层感知机:\(score(q,k)=v_a^\top tanh(Wq+Uk)\)