概论 ¶
约 564 个字 24 行代码 3 张图片 预计阅读时间 2 分钟
什么是超算 ¶
超级计算机,是指能够执行一般个人电脑无法处理的高速运算的计算机,规格与性能比个人计算机强大许多。
———— 维基百科
开发工具 ¶
SIMD: AVX/SSE¶
高级向量扩展指令集(AVX)是 x86 架构微处理器中的指令集。
———— 维基百科
单指令多数据流(Single Instruction Multiple Data
在 x86 架构下,SIMD 一半和 SSE 和 AVX 等指令集联系在一起,SSE 和 AVX 指令集中提供了大量可以单指令操作多个数据单元的指令
下面是 SISD 和 SIMD 的比较
SISD
SIMD
通过一条 CPU 指令,并行执行 8 个 float 的加
SIMT: CUDA/ROCM/OPENCL¶
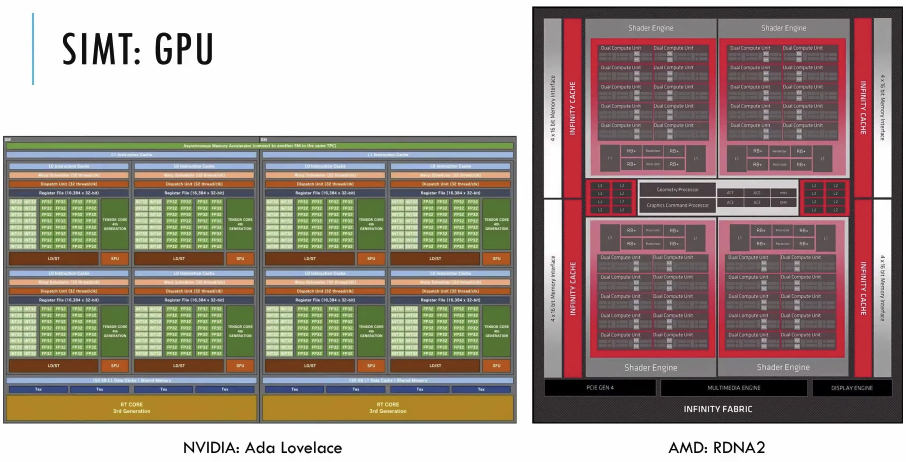
CUDA(Compute Unified Device Architecture, 统一计算架构)是由英伟达 NVIDIA 所推出的一种集成技术,是该公司对于 GPU 的正式名称。 ROCm 是 Advanced Micro Devices(AMD)的软件栈,用于图形处理单元 GPGPU 编程。 OpenCL(Open Computing Language,开放计算语言)是一个为异构平台编写程序的框架,此异构平台可由 CPU、GPU、DSP、FPGA 或其它类型的处理器与硬体加速器所组成。
———— 维基百科
CUDA
__global__ void vectorAdd(float* a, float* b, float* c) {
int tid = blockIdx.x;
if (tid < 8)
c[tid] = a[tid] + b[tid];
}
OpenCL
_kernel void vectorAdd(global const float* a, global const float* b, global const float* c) {
int gid = get_global_id(0);
if (gid < 8)
c[gid] = a[gid] + b[gid];
}
MULTI-THREAD: OPENMP¶
OpenMP 是一套支持跨平台共享内存方式的多线程并发的编程 API。
———— 维基百科
为了利用多线程,我们可以使用一些更低层的库进行开发(Linux 下的 pthread
OpenMP
性能调优 ¶
CPU¶
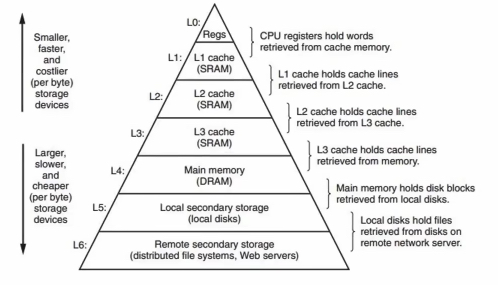
- CPU 通过将数据缓存到 L1/L2/L3
- Cache 中避免对内存的频繁访问造成的低效
- 优化方法
- 循环展开
- 内存预取
- ...
- CPU 本身是一个流水线结构,执行每一条指令分为多个阶段,流水线地执行。
- 在出现分支的地方可能导致流水线无法正常被填充
- 优化方法
- 分支预测
GPU¶
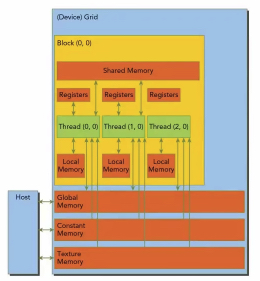
- CUDA 开发中的问题
- 线程束分化
- 理解 GPU 内存模型
- 并发
- ...
RDMA¶
在数据中心领域,远程直接内存访问。适合大规模并行计算机集群。