Fault-tolerant Key/Value Service¶
约 1305 个字 1 张图片 预计阅读时间 4 分钟
Abstract
- 这是一个基于 Raft 和 RSM 的 KV 数据库系统,多个 server 通过 Raft 协议来同步操作日志,保证所有 server 上的状态机保持一致;
- 与 Lab2 类似,只是该服务并非单一 server,而是多个 server 组成的 Raft 集群;
- home: https://pdos.csail.mit.edu/6.824/labs/lab-kvraft1.html
Tip
- client.go: 供应用程序调用,发起
Get()和Put(); - server.go: KV Server,接收 client 的 RPC 请求,并将其提交给 Raft 集群;
- rsm.go:复制状态机层,连接 KV Storage 和 Raft 的桥梁,负责将操作提交给 Raft、从 Raft 应用已提交的日志条目到状态机,以及管理快照;
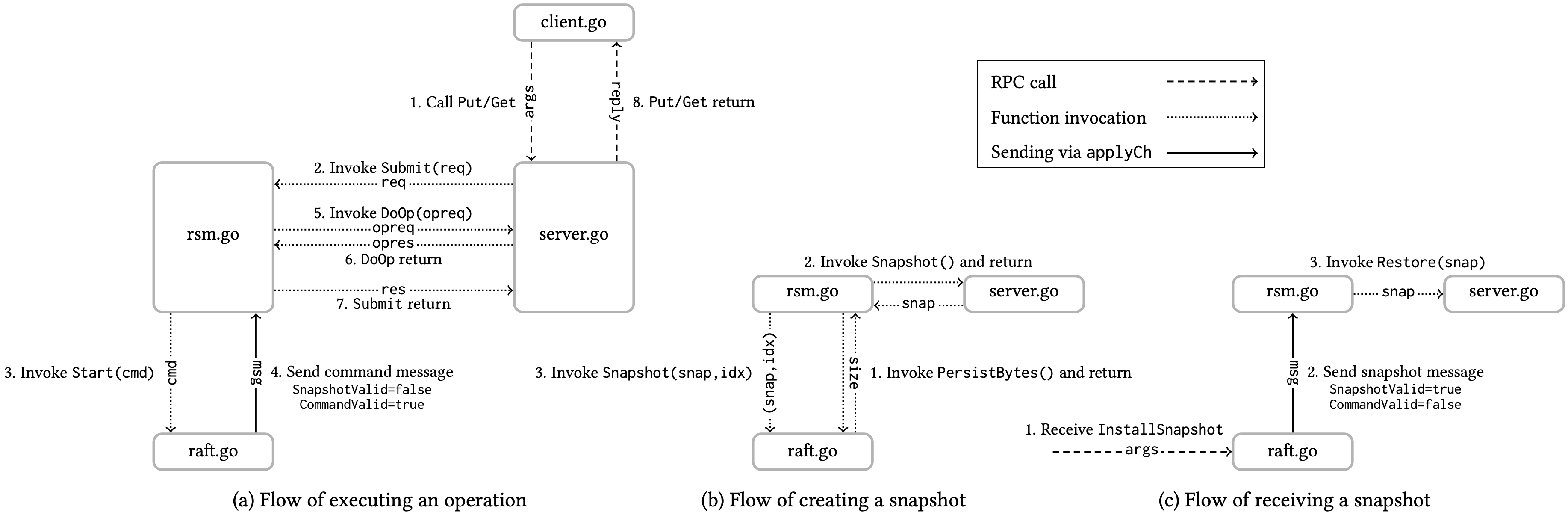
Part 4A: replicated state machine (RSM)¶
replicated state machine (RSM)
- 实现 rsm.go 中的
Submit()和 一个reader()goroutine; - 网络分区情况下如何保证数据一致性?
- raft 节点 kill 时,applyCh 的处理?
数据一致性 ¶
可能因为网络分区、节点宕机等,会发生 leader 改变,client 只有在操作真正被正确的 term 提交、且内容未改动时,才能收到 OK。
- 为了保证数据一致性,rsm 维护一个哈希表 opMap:
- key 为 Id,表示 op 的唯一 id,可以用 log 的 index 表示;
- value 为 opEntry,包含期望的 Term、Req 和结果 channel;
- 如何保证数据一致性:
- opMap 中是否存在 Id:
rsm.opMap[applyMsg.CommandIndex]
- Req 比较:从 applyCh 读取到有 log 提交,就可以去应用,但是这个 Req 可能是旧 leader 的未提交 log,因此需要和当前 client 发起的 Req 做对比:
!reflect.DeepEqual(opEntry.Req, op.Req)
- Term 比较:Term 的改变可能意味 leader 的改变,旧 leader 的未提交 log 可能会被覆盖:
opEntry.Term != applyMsg.Term
- opMap 中是否存在 Id:
当 raft 节点 kill 时关闭了 applyCh,而此时 applier 还在把提交的命令发送给 applyCh,导致错误。
- 当
Kill()时,applyCond.Broadcast()唤醒所有等待的 goroutinue,并且用sync.WaitGroup等待所有 goroutine 退出; - InstallSnapshot 中也会发送快照到 applyCh,因此要判断 rf 是否
killed();
Submit()¶
- 向 raft 使用
rf.Start()等待 raft 提交请求,并发送给 applyCh; - 建立 OpEntry,记录期望的 Term、Req 和结果 channel;
- 用 select 阻塞等待结果;
reader()¶
- 轮询 applyCh,读取已提交的 log;
- 若 Raft 异常关闭,需要向 opMap 内所有待处理的 opEntry 发送
ErrWrongLeader,并清空 opMap 后退出; - 若 applyMsg 正确,则执行状态机
rsm.sm.DoOp(op.Req),在加锁前执行,保证每个已提交日志都被应用一次;- 如何保证只应用一次?reader() 从 applyCh 逐个接受日志,raft 本身保证每个已提交日志只应用一次,不会重复发送同一个
CommandIndex的 applyMsg,所以 DoOp 只会执行一次; - 为什么在加锁前? 因为 DoOp 可能是耗时操作,若在加锁后执行,可能会阻塞其他 goroutine 的访问,影响性能;
- 如何保证只应用一次?reader() 从 applyCh 逐个接受日志,raft 本身保证每个已提交日志只应用一次,不会重复发送同一个
- 三层验证,opMap 是否存在
CommandIndex、Term是否匹配、Req是否匹配,正确与否都要做相应处理和回复;
Part 4B: Key/value service without snapshots¶
Key/value service without snapshots
- 使用 rsm 来复制一个 KV Server,每个 kvserver 都会关联一个 rsm/raft 节点,client 通过
Get()和Put()RPC 向其关联的 kvserver(raft leader) 发送请求,kvserver 将Get()/Put()提交给 rsm,rsm 使用 raft 对其复制,并在每个节点上调用 DoOp,应用于 KV Database; - 实现一个在没有消息丢失且没有故障的环境下能正常工作的 KV 服务;
- Clerk 不知道哪个 kvserver 是 Raft leader, 应该如何处理?
- 如果故障如何处理?
client¶
leaderId:Clerk 维护当前认为的 Raft leader 的 kvserver id;clientId:Clerk 的全局唯一 id,用于 server 识别请求来自哪个 client;requestId:Clerk 维护每个 Request 的唯一 id,用于 server 识别同一个 client 的重复请求,每次Put递增;
Get()¶
- 同 lab2;
- 轮询 leader,每次读
leaderId然后向对应 server 发送 RPC; - 如果 RPC 失败或返回
ErrWrongLeader,则尝试下一个 kvserver,直到成功为止;
Put()¶
- 同 lab2;
requestId++,同clientId一起发送给 server;- 轮询 leader 并处理结果,注意是否首次发送请求;
server¶
kvMap: 存储所有 kv 及其对应版本号,{key: (value, version)};clientPutResults: 缓存每个 client 的最新Put()结果,当重复 Request 到达时,直接返回缓存结果,保证线性一致性;
DoOp()¶
- 根据
req.(type)判断是DoGet()还是DoPut(); DoGet():同 lab2,从kvMap中读取 key 的值,返回ErrNoKey或对应 value;DoPut():- 同 lab2;
- 检查
clientPutResults,如果是重复请求,直接返回缓存结果; - 否则,更新
kvMap,并将结果缓存到clientPutResults中;
Get()¶
- 向 rsm 提交
Get请求,等待结果返回;
Put()¶
- 向 rsm 提交
Put请求,等待结果返回;
Part 4C: Key/value service with snapshots¶
Key/value service with snapshots
- 修改 rsm,使其能够检测到持久化的 Raft 状态何时变得过大,然后将快照交给 Raft,以便节省日志空间并减少重启时间;
- 实现
Snapshot()和Restore()方法,rsm 在什么时机调用? - 除了 server 状态外,快照中还应包含哪些数据?
Snapshot()¶
- 对 server 的 kvMap 做快照;
- 调用时机:
- 当 snapshot 的大小超过给定的 maxraftstate 时调用;
- 应在 log 应用后即执行
DoOp()后调用;
Restore()¶
- 在 Raft 中收到快照,并在 server 中恢复数据;
- 调用时机:
- 当 RSM 重启时 snapshot 大小不为 0 时调用;
reader()中接收到快照时调用;